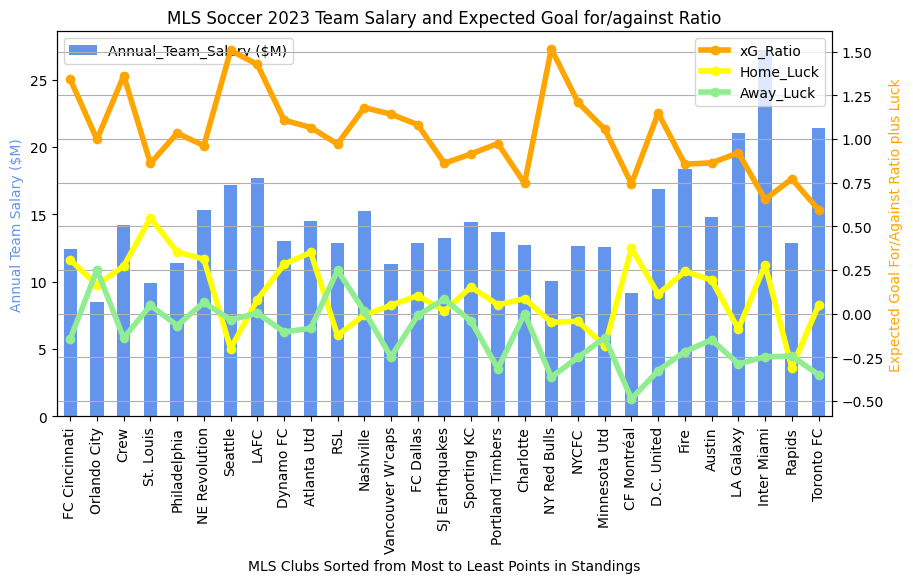
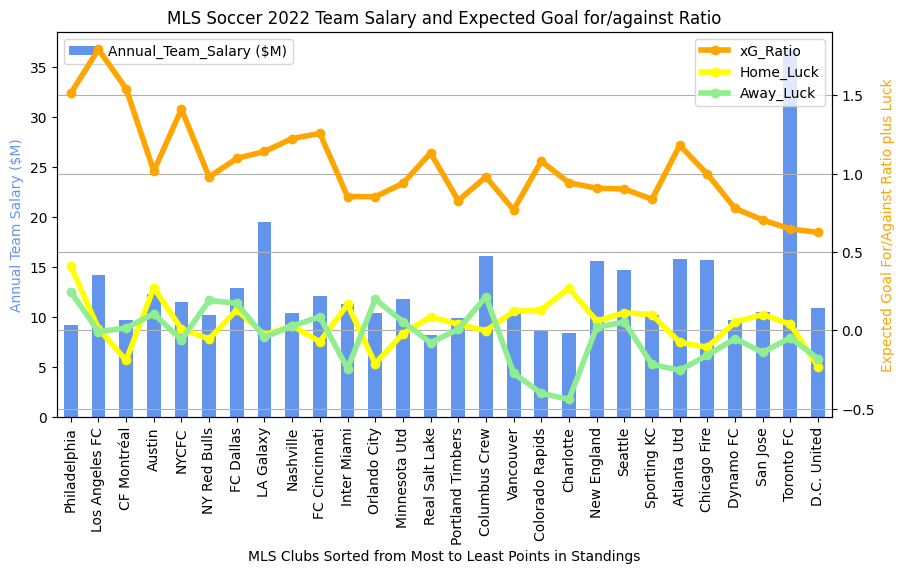
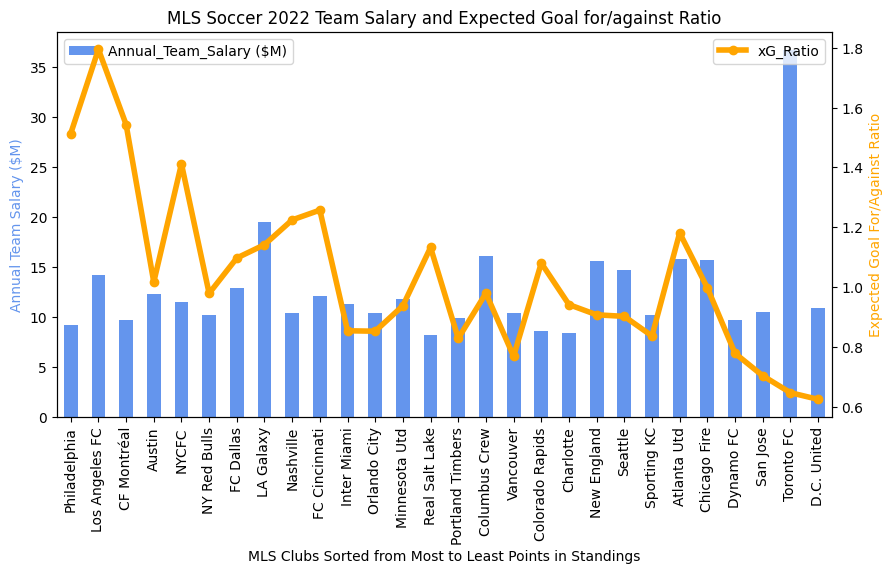
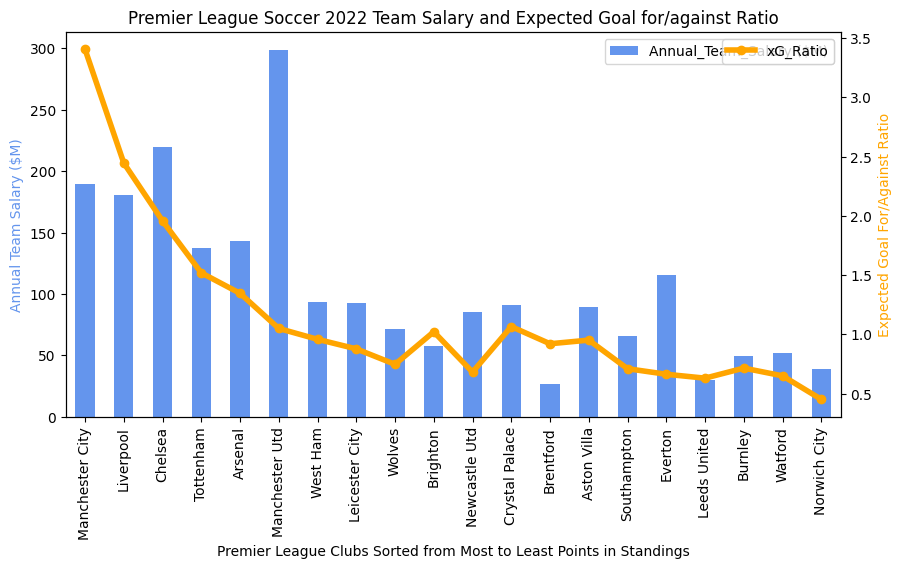
In the previous entry, I compared the expected goals / Luck metrics between the last two completed MLS seasons. Now that the Premier League season has come to a close, we can do the same thing to see if any new patterns jump out at us.
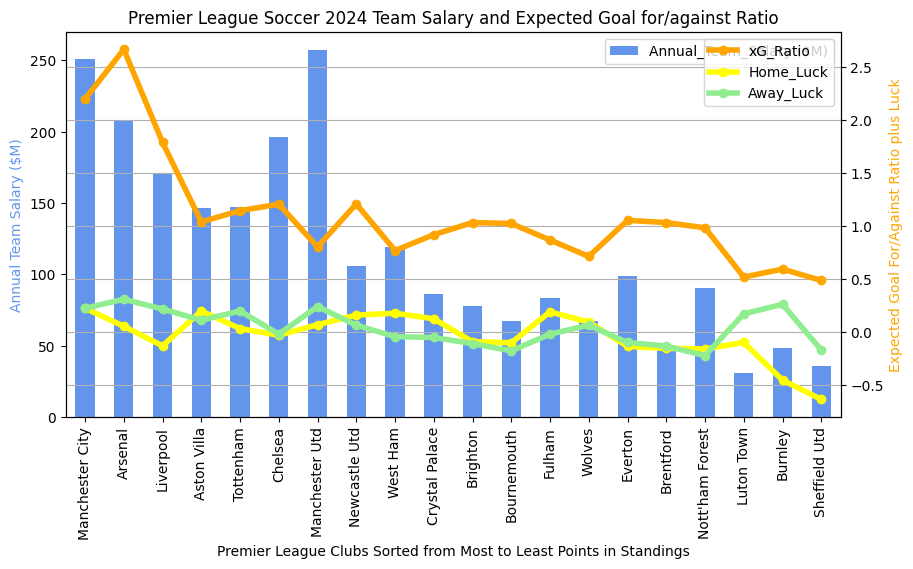
A quick overview of what we see above would go something like this… Manchester City finished at the top of the league in points, followed by Arsenal. The teams are sorted by final point tally from left to right on the chart. The three teams to get relegated are on the far right (Luton Town, Burnley, and Sheffield United). Things I see:
- Man City and Man U always have the highest salaries. Lately Man U has been inconsistent in play and has been finishing out of the top four. Their expected goals for/against ratio is a bit lower then their direct neighbors in points (Chelsea and Newcastle). We don’t know exactly why, but it reflects their overall efficiency at taking and preventing good shots. For some reason, Chelsea and Newcastle were a bit more efficient at ensuring that they got more good shots than their competitors in matches. Interestingly, we see West Ham sitting at about 1/2 Man U’s salary but with nearly the same xG ratio. But West Ham finished 8 points lower than Man U. Perhaps there are ways that expensive players help other than in the xG ratio. I might imagine that expensive, ostensibly better players may be slightly more likely to score when taking a good shot or to prevent an opponents good shot from going into the net.
- Salary in the Premier League seems to always be more important than in MLS. The top salaries are always in the top 1/2 of the league in points in the Premier League, but this is not as strongly observed in MLS.
- Luck. Sometimes there’s an interesting disparity between luck at home and luck on the road (the yellow and green lines respectively). Near the top of the rankings, we see that Liverpool’s home luck is below zero (meaning that they score less goals on average than their expected goals would predict) but their away luck is above zero. I did a quick google on Liverpool and “home luck” and found this. So others have noticed this, but I don’t see that they have observed that most of Liverpool’s luck has been in away venues. On the bad side of the rankings, though, we see large differences open up between home and away luck. All three relegated teams really struggled on the road to score up to their expected goals (i.e., good shots weren’t going in). Clearly this is an important measurement for identifying that your team is in big trouble. Conversely, though, if your team finishes positive on both home and away luck, it seems that this can offset a big salary differential (see Arsenal, Aston Villa, Tottenham, and Newcastle, all in the top half of the league in points).
2022-2023 Results for Comparison
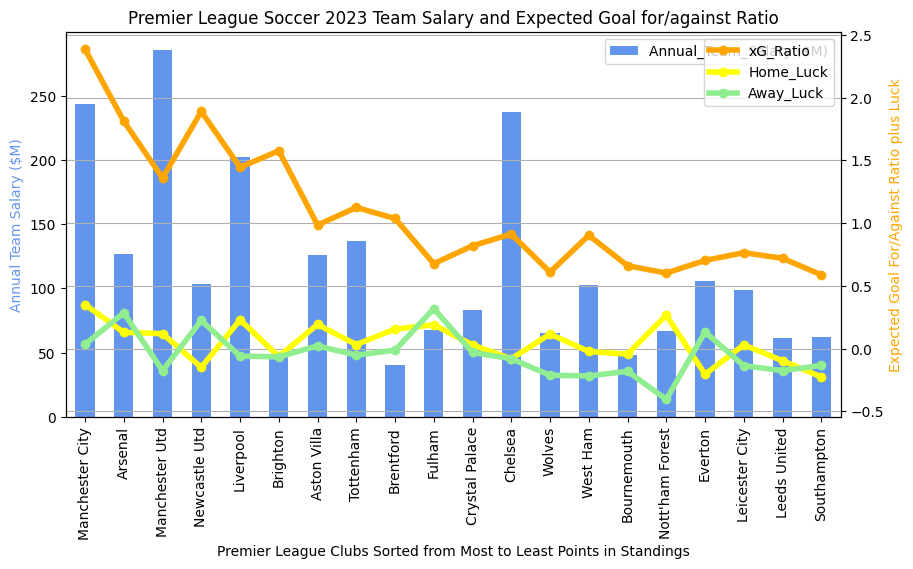
Stuff to discuss:
- Chelsea was a strange outlier during this season regarding salary and final point tally. Their xG ratio is below 1 and both their home and away luck are negative. Efficiency seems to have been an issue. Compare to Fulham who finished 8 points ahead of them with somewhere around 1/4 of the salary. Fulham had lower xG than Chelsea this season but had great luck both home and away. Note that Chelsea finished higher in 2023-24 and Fulham finished much lower as their luck regressed back to the mean.
- There’s also a big delta between Nottingham Forest’s home and away luck during this season. They finished just ahead of relegation, but maybe they did so just by the skin of their teeth due to their abysmal away luck (lowest in the league). Note that in 2023-24, Nottingham again skated just ahead of relegation, but both their home and away luck were just below zero. Speaks perhaps to inconsistency in scoring off of good chances, probably a predictor of a future relegation.
- We again see a number of teams in the top half where positive away and home luck offsets a salary gap. Note Arsenal, Aston Villa, Brentford, and Fulham all in the top half.
LINKS to Other Soccer Analytics Entries
- Soccer Analytics Series Intro
- MLS and Premier League Comparison
- Home and Away Luck Metric
- Does Counterpressing Work? Evidence.
- Evaluation of Outcomes using the Luck Metric
- More Analysis using the Luck Metric
- Soccer Analytics in Practice – Youth Soccer Example
- xG and Luck update on recent MLS season
- xG and Luck update on recent Premier League season