This above chart is a bit different because it shows the cumulative number of COVID-19 cases in the state for each age demographic divided by the total population in the state of that age group. This allows us to see how COVID-19 is really affecting the different age groups. A few things that are interesting…
1) The true rate of infection for 3 groups is pretty much the same. The 20-44 age group always has the most cases by raw number, but when you consider there are more of them than any other group, you can then see that they’re not excessively effected compared to other groups.
2) The 65+ group has less cases by close to 1/2 of the top groups. This makes sense because I’d imagine that many of them are being more careful due to the severity of the disease for those groups.
3) The under 20 group is much less likely to get infected. This may partially be because a good number of people in this group aren’t economically active and schools have been closed. Or maybe their immune systems are better tuned to the disease and they never show symptoms. Remember these cases are confirmed by tests, so there may be many people who never show symptoms and never get tested who have been infected.
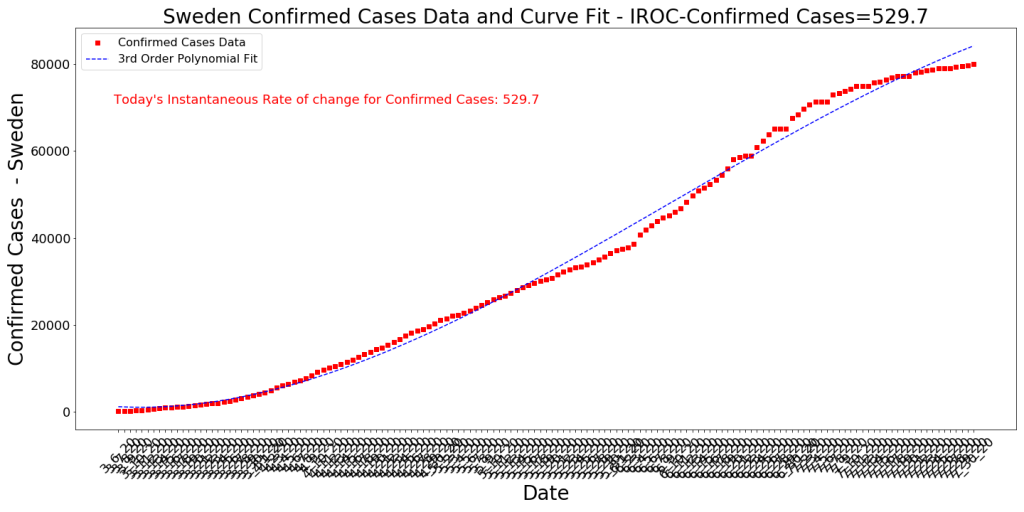
4) I’m very surprised at the lack of effectiveness of the state measures taken in late June. Pretty much every county in the state issued facemasks in public proclamations and the economy was essentially closed again. Still, we see no impact on cases for basically 6 weeks, then all of a sudden all the age groups show a marked decrease (the red vertical line). I truly expected the state measures to show a dramatic effect in 2-3 weeks (since the cycle time of the disease ia about 18-21 days). Very strange, but similar to what has been seen in other regions. Sweden (see below) had a sharp downturn in cases just like this and they had very few state measures taken. Makes me curious about what is really causing the rates to make such sudden changes.
5) Testing: The chart below tells the testing story. People have noted to me that media outlets are suggesting that falling case numbers have to do with the decreasing numbers of tests. The way I look at this data is this: First off, testing in Arizona is not strategic and random. People get tested because they feel sick or they work in jobs where there’s a high probability that they could be sick. This means the numbers of tests conducted has a high severity bias. So what this data might be telling us is that every day there are fewer people who feel sick who decide to go get tested and that an even lower percentage of these people are actually confirmed positive with COVID-19. This seems to indicate to me that the decreasing case numbers are probably legitimate.