

Here’s an applied approach to the hard problem of what is referred to as “knowledge representation“, where we provide structures for machines to capture information from the world and represent it as knowledge that can be used to solve problems. There’s a long history of research into this challenging field and much of that research has failed to result in simple, approachable methods.
As someone who thinks hard about building intelligent assistants that enable more effective human decisions (rather than intelligent agents that make their own decisions), I have spent time and energy to approach the knowledge representation problem from this context. This means I work to build systems that can extract and build knowledge from sets of texts and documents that humans will never be able to read through. This system can then provide the human decision maker information visualized in a simpler way that will then improve their decisions.
Example
Context: I was looking for a set of documents to demonstrate my techniques on around the time the Ukraine war was about to begin. As it turned out there had been numerous reports and analyses developed anywhere from 6 months before the war begin right up to the days before the war started.
Goal: Determine AFTER the war began if there was anything in the early analyses that predicted what was going to happen.
Outcome: As you’ll see, interesting predictions could be distilled out of “questions” presented to the knowledge graph.
Process:
- One of the hard problems with this kind of analysis is puling data out of the texts that one finds scattered across the internet. I tend to use search engines to find files that I download and then process in bulk. Generally these documents are in PDF formats, which generally makes them a bit harder to process. Automating accurate processing of PDF files is beyond this scope, but it’s a bridge that probably must be crossed for someone interested in Natural Language Processing and Knowledge Representation.
- Knowledge Graphs: Building a knowledge graph isn’t nearly as difficult as it sounds, but it requires a few things. A toolkit like the python Natural Language Toolkit (nltk) is very useful, as it has the necessary ingredients like sentence tokenization, word tokenization, and parts of speech classification. Here’s a great overview from a notebook on Kaggle, the data science competition site. One first will use all the downloaded texts to build a “master” knowledge graph, that consists of Subject->Action->Object “triplets” built into a network graph. This graph will be incredibly dense, but what will emerge are central concepts that are frequently noted in the texts.
- “Questioning” the Knowledge Graphs: This may also be viewed as filtering central topics out of the master knowledge graph by asking questions of the graph. For instance, the question, “Will Russia’s invasion trigger an economic impact and increased immigration” provides a filtered view of the master knowledge graph that looks like the below:

If you look closely, you will notice that the nodes (blue) are nouns and an arrow points from the subject to the object. The arrow is referred to as the “edge” and it is labeled with the action verb in red. This is interesting and makes nice pictures in presentations and papers, but it becomes useful when the graph is converted into a table of triplets from the filtered graph that point to the context from the document where the triplet was extracted. At this point, the researcher finds the sentences that generate the “answers” to the question. See example of this context below.
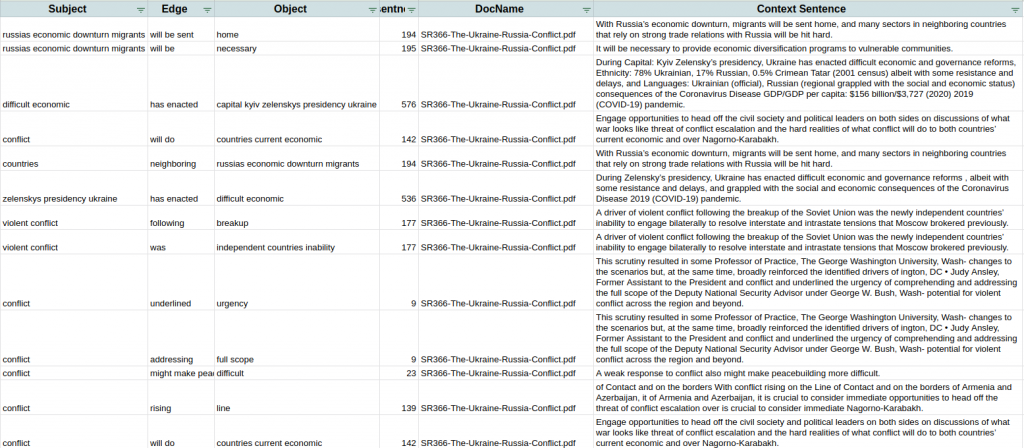
As you can see, there were multiple discussions of immigration and economic challenges in the set of documents and the “answers” to the question found in these documents are captured in the table (Note: I’m just showing the first few rows of the answers). If one wanted to conduct a very thorough literature search of a much larger set of documents, it is likely that this method could save countless hours of digging through documents and enable quicker and better decisions on the subject.