Check out the six part series on the creative elements behind “The Prophet and the Queen”. Find the whole playlist here on YouTube! Each video is somewhere between 5-10 minutes, so they don’t require a huge investment! 🙂
Join author W. Tod Newman as he takes you behind the scenes of his acclaimed historical novel “The Prophet and the Queen.” In this six-part series, Newman reveals the creative process, historical research, and literary decisions that brought the world of ancient Judah, Babylon, and Egypt to life. Discover how he humanized the biblical prophet Jeremiah, crafted complex relationships between characters, and wove historical events into a compelling narrative. Whether you’re a history enthusiast, spiritual seeker, or lover of literary fiction, these insights will enrich your reading experience and illuminate the timeless themes that make this ancient story resonate with modern readers.
It has been a few years since my last novel was released. At the time I did a long series on self publishing (find it here). I found that the series was helpful to me even in this latest effort.
For those who are arriving here after downloading my most recent novel, I have a question…
How interested would you be in my trying to publish a novel serially (like a new chapter per week)? I have tried this in the past, but it seems like people didn’t make it to the site or didn’t find it compelling.
Leave me a comment with your thoughts… I’d love to be able to revive the notion of serially published stories, but wondering if that era will never happen again in the modern era.
It has been a few years since my last novel was released. At the time I did a long series on self publishing (find it here). I found that the series was helpful to me even in this latest effort.
Check out the new novel over at Amazon (e-book or paperback) or Lulu (paperback). The free e-book promotion has finished, but we saw nearly 1K downloads, which placed the book at #1 on Amazon Kindle for a couple of days. Just a couple of days, of course.
I asked claude.ai to build a promotion less than 350 words for this book and this is what it gave me. Not bad!
A biblical epic of faith, power, and prophecy in the ancient world
Journey to the tumultuous world of the ancient Near East in this gripping reimagining of the prophet Jeremiah’s extraordinary life. As empires clash and Jerusalem faces destruction, one reluctant prophet stands at the crossroads of history, torn between divine calling and human frailty.
Jeremiah never wanted to be The God’s voice. Yet as Babylon’s armies threaten everything he loves, he finds himself caught in a dangerous spiritual battle against the seductive Queen of Heaven who tempts his people away from their faith. From the mud-filled cistern where his enemies left him to die to the courts of Pharaoh himself, Jeremiah’s journey reveals the high cost of speaking truth to power.
With rich historical detail and psychological depth, “The Prophet and the Queen” explores:
The fall of Jerusalem and the exile that changed Judaism forever
The complex web of ancient empires—Babylon, Egypt, and Assyria
The intimate struggles of a prophet who questions his own worth while remaining faithful
The timeless tension between cultural assimilation and preserving identity
Perfect for readers of Francine Rivers, Geraldine Brooks, and Tessa Afshar, this meticulously researched novel brings biblical history to vivid life while exploring questions of faith, purpose, and personal integrity that resonate across millennia.
“A mesmerizing tale that humanizes one of the Bible’s most enigmatic prophets while illuminating the turbulent world he inhabited. Readers will be swept away by this powerful reimagining of ancient events that shaped religious history.”
The season has less than 20 matches remaining, so I figured it might be a good time to evaluate where the clubs stand regarding the xG ratio, luck, and salary. Refer to past analyses in my soccer analytics category to see previous years.
What I’m curious about is if these measures reveal the likelihood of relegation, for, say, Manchester United or Tottenham. Both of these big, wealthier clubs are having really horrible years. Lets see what the data tells us.
2024-25 Season Current Results
Analysis of the Top of the Standings
One thing that stands out is how Liverpool and Arsenal have by far the highest xG ratios. That means, based on the shots they’re taking and allowing, their play is extremely favorable for wins. Both of these clubs are at the top of the table, so there’s a chance that this ratio is (unsurprisingly) quite correlated with points in the standings. Frequently we see that salary (the blue bars) are the most correlated element to points, but this year we see Man City, Man U, and Chelsea all struggling down the standings but with very high salaries. Nottingham Forest feels like they’re punching way over their weight with one of the lowest salaries in the entire Premier League, though. I notice that their xG ratio is a bit lower than the 3-4 clubs behind them in the standings and their away and home luck factors are both greater than zero. It is interesting to notice that though Nottingham finished quite low in the Premier League standings last year, they happened to have the worst away luck factor in the league. A few breaks going their way in 24-25 and now we see them in contention for a Champion’s League slot!Stay tuned, however, to see if they will settle a few spots lower in the standings based off of their current year’s above average luck factor. Additionally, it would seem that Chelsea could move up if they improve their home luck factor because their xG ratio is third highest in the league.
Analysis of the Bottom of the Standings
Our three teams in relegation positions right now (and also the Wolves and Everton) all seem to deserve their placement. Having an xG ratio below zero indicates that their opponents are getting better opportunities for scores than their own offense. This is obviously a recipe for a lot of losses. I kind of expected Ipswitch Town to struggle this year and get relegated, but their position in the third slot is possibly because their luck factor away (their overperformance of their expected goals) is the highest in the league. This is probably not likely to continue, so if I was an Ipswitch supporter, I wouldn’t have very high expectations for their last 17 games.
Bernardino Luini, Milanese, c. 1480 – 1532 , “A Portrait of a Lady”, National Gallery
The Portrait of a Lady is a novel by Henry James, first published as a serial in The Atlantic Monthly and Macmillan’s Magazine in 1880–81 and then as a book in 1881. It is one of James’s most popular novels and is regarded by critics as one of his finest. I picked it up recently after once again rejecting James Joyce’s Ulysses for being insipid and unreadable (more on that perhaps in a different post). After confronting Joyce’s vain, meaning-free language, Henry James’ writing style was very pleasant and quite thought-provoking. Like Joyce, James is wordy, but his sentence construction conveys his thoughts clearly, as opposed to Joyce, whose experimental prose seems to primarily convey feeling and sentiment and often resists anything that has the appearance of truth. Henry James, however, is very interested in his characters and their depth and uses them to convey hard truths about life. This is my opinion, of course and it is your right to disagree!
In this book, James brings to the surface the conflict in his time between the spirit of independence and social norms. Throughout the book, James uses America and Europe as symbols of these qualities. America, of course at the time was a symbol of innocence and individualism. Europe, on the other hand, was revealed as a picture of sophisticated tradition and social conventions. Things have changed quite a lot since the late 1800’s, and a current author might not choose America and Europe to illustrate this point any longer, but there are plenty of targets available. Independence is viewed differently in the modern west than it was in Henry James’ time and while it may have been surprising and refreshing to read about a bright, independent young woman in the late 1800’s, in the modern west, it would not capture the same level of interest, because the notion of pursuing independent thinking is encouraged by society. Even in countries touched by communal or Marxist traditions, the idea of being an independent thinker is generally accepted. In both types of societies, though, I’d submit that the actual practice of independent thinking is often discouraged through various suppression techniques and fashions. That said, we see our main character, Isabel Archer, early in the novel and her notions of independence and the unfettered pursuits of experience stand out from the European formality and fatalism that surrounds her. The reader finds themselves excited to see her challenge and conquer these societies with her intelligence and energy. All goes well for her and she comes into a small fortune at the death of an Uncle and the intervention of a well-intentioned cousin. Isabel demonstrates her freedom and desire to follow her own unique path by rejecting marriage proposals from a British Lord and an American businessman, both of whom meet her and love her before her fortune is made.
To avoid spoilers, what we see next in the novel confirms many prejudices about how one’s fortune can negatively impact not just a life, but also one’s true independence. Isabel finds herself a target of scheming by unscrupulous expatriates and life crashes down hard on her. We see very complex characters, one is truly Machiavellian and evil in his self-regard and vanity. Another chooses to demonstrate proper behavior in society to set up complex social networks and schemes that solve her money problems (and also other, more challenging issues). One of my favorite characters is Isabel’s American friend, Henrietta, a direct and somewhat nosy news reporter. Henrietta grows significantly during the novel and becomes a true friend to Isabel by the end.
During the unfolding of the novel’s plot, we find Isabel becoming a loving step-mother to young Pansy Osmond, who looks to the reader as what we might expect a convent-raised wallflower might look. By all appearances, she has no imagination and has been trained to be passive and obedient to her manipulative father. To our modern sensibilities, her character for much of the book is disappointing, but when we are able to see a bit deeper beneath the surface, we find that our modern western prejudices have betrayed us a bit. Perhaps Pansy is more complex that we thought? This is the thought that I might close with because The Portrait of a Lady has much in it to trigger our modern fashions. Many will be unable to get beyond this, as our culture maintains just as strong a hold on our imaginations – and is as insidious – as the late 1800’s European behaviors that we have learned hostility towards. We moderns unfairly judge many of the characters of this book for actions and behaviors which are merely manifestations of their culture, but we are challenged by other characters whose narcissism and manipulation look like the evil that we often choose to paint over.
AI generated Image “visualizing the management of worker motivation”
I mentioned in my last post on knowledge-work productivity that understanding how to manage motivation to do specific tasks will result in overall higher productivity. As someone who has thought about this (and experimented with approaches) for years, here are some of my thoughts:
Set up Spaces Focused on Improving Motivation: This is a general idea to increase your productivity overall. It also includes the notion from my last entry on investing in quality tools. I’ve learned that it is not smart to skimp on the cost of tools (computers, notebooks, monitors, other work infrastructure) that are higher quality and are likely to give you joy to work with. Obviously, one can’t always have the best of everything, but if there are key, strategic tools that you work with, my experience is it is smart to spend the extra $50 or 100 bucks. Especially for a tool you may spend years working with. Key examples of this are 1) my mechanical keyboard – typing on this keyboard is satisfying in some weird way and I find that I’m unhappy working without it. 2) My noise cancelling Sony wireless headphones – What a lucky thing that I spent the money (they’re not cheap) right before COVID to buy these things… I originally had intended them for use on flights, but of course, COVID ended that idea and it morphed into use during Zoom calls. Was an absolute lifesaver for remote work and I was constantly grateful for them.
In addition to quality tools, though, envisioning how your whole workspace could be “architected” to draw you in to work more effectively is time well spent. Things like KVM switches or USB hubs that allow the switching between computers are important for me, because they allow the quick, painless switching between a work computer and one or two personal computers. If you have a powerful personal computer (I use a Macbook Air and a powerful Linux workstation with big GPU’s) or two that are better for use with certain kinds of tasks, then the ability to switch common resources like the big monitors, mechanical keyboard, wireless mouse, or upgraded camera between them makes switching a breeze.
Obviously things like a good chair and desk are important. Some people revel in their standing desks because it allows them to work in completely different contexts. I also like my office decorations (lots of tall ships and John Wayne paintings) because they make me happy to be in the office, which can improve my motivation to work.
Track your Work: I think we all feel motivated when we make visible and measurable progress on a task. This, to me, is the chief value of a tracking schedule. I like checking off the boxes on a task! An example beyond the tracking schedule is the word count trackers that I use when I’m working on a book. I always have a daily goal to write some manageable number of words (usually like 100 or so) in the hope that I actually sit down, get in the zone, and crank out thousands of words. Knowing the value of visibility of work, I add to this a tracker where I have two columns, date and cumulative word count. I then do a simple line plot that shows the slope of my writing accomplishments. Some days, I write more and then get to see a steep slope of word count output for the day or week. This motivates me to keep it going! I refer to the word count tracker as a commitment device, but I also think of my IOS “Streaks” app (well worth the $3 or so on the app store) is also a commitment device that also helps build habits. And building habits gets us in that seat to do that writing (or gets us to the gym to lift, or reminds us to floss every day).
Manage an Overall Work List: I have found that having a quite varied list of things that need to be accomplished helps with the times when I just don’t feel like doing anything. I’ve learned that when I feel this way, that I can almost always find something on the overall work list to do. If I’m feeling more like refinishing a piece of furniture than building the AI classifier for the dataset I’ve been looking at, I am able to work without any sense of guilt on the furniture. My experience is that there will come a moment when I’m very motivated to explore that dataset and if I ride the wave of that motivation, I’ll do the work much more efficiently.
Know When You Work Well on Types of Tasks: I know that in the early morning, I’m much, much better at tasks that require creativity and challenge my thinking. Conversely, right around 2 PM after I’ve eaten lunch is NOT a good time for these tasks. I have found that 2 PM is better for walking around and doing gardening tasks or working on other more physical kinds of chores. Don’t fight these kinds of patterns!
Celebrate Completed Work: I have a strong bias to finishing tasks that I’m working on instead of just pushing them forward a few steps. I think this allows one to be much more productive. So to support this, I celebrate completions. Perhaps finishing a major task means that I drive to Dairy Queen for a sundae. Or maybe it just earns me a short nap (I’m a big fan of the 13 minute nap for rejuvenation). The act of celebrating a completion is important and helps you build enthusiasm for the next task.
Work to Identify how to fit your Motivation into an Employer’s Goals: OK, sometimes your employer doesn’t have the intimate knowledge of your motivation cycles and just wants you to work 9 hours straight on the most important tasks. If anyone is able to do this day after day, I’d love to know about you! Your employer isn’t really able to measure your productivity and assumes that measuring your hours-worked (and maybe how late you stay at the office) is the best proxy for productivity. Of course this is completely false. Any employer who cares at all about quality and productivity SHOULD be focused on tapping their employees’ best hours for the jobs. So many mistakes have been made by employees who were burned out, mentally exhausted, and working on activities they are far over-qualified for. Since the employer can’t manage this, somehow the employee needs to focus hard on maximizing their productivity through working tasks when they are most fit (and motivated) to work them. There is probably a whole lot more to be said about this, and possibly some of it would be controversial. I heard the quote once, “good employees do exactly what their employer tells them to do. Great employees conspire to make their employer astonishingly successful.” This is interesting to consider, especially in light of managing your motivation cycles.
Here’s a bit of a diversion from my normal data-oriented posts, but in a previous job, as a data-driven systems thinker it was natural for me to explore and try to understand how to measure productivity and cycle time. The work outcomes that the organization needed to understand better tended to be heavy on system design tasks but also extended into the work needed to set up product lifecycle cash flow.
Background on Productivity in Design Work
It was always a struggle to measure productivity (and cycle time) in this kind of environment, because it was extremely challenging to identify and measure the most important, value-producing events in the workflows. For instance, in system design, it was extremely easy to measure the productivity of one of the major bottlenecks in the process… (drum roll)… drafting! Why is drafting a bottleneck in the design of a system? Well, not only does someone in a factory have to assemble the product you just designed, but you also have to ensure that the supply base can be enabled and protected. Often the bill of materials on a drawing is the entry point for most of the complex activities performed by the supply chain organization. Additionally, quality needs to be protected and the “recipe” for building your system cannot be lost. All of these objectives, always made drafting a long, tedious process that designers and manufacturing engineers both expressed impatience. I went a bit long on this, but maybe you can see why productivity is easy to define and measure. The drafting team is working on one product, generally is not multitasking, and start work and complete work date and times are easy to capture – allowing the cost of the drafting product to be easily normalized by the hours spent (resulting in dollars per hour). Perhaps even the whole process can be measured from logs built automatically by the drafting software.
However, most of the rest of the design process is not so easy to measure. It spreads across many teams, all of whom have some sort of dependencies on other teams, each of which has it’s own “special sauce” and tasks which build upon tasks. Mastering queueing theory helps in manufacturing facilities where assembly tasks depend on multiple preceding steps is hard but doable because in manufacturing, the product is generally always visible to the eye. In design, however, the product can be ideas, processes, models, and pieces of documentation and is rarely visible in the same way.
So with that as background, I recommend the following YouTube video if you have interest in improving your true productivity in a “knowledge work” environment. I agree wholeheartedly, but watch the video and I’ll add my fourth principle to Cal Newport’s three that he offers.
OK. Did you watch the video? What does Cal offer up as his three principles?
Do Fewer Things – Or better, “Do fewer things at once”. We all can chant “multitasking is a productivity killer”, but most of us still think we’re pretty good at it. Regardless, however, the point is not that you’re bleeding productivity, but that you’re probably doing things that have no impact on your life, your enjoyment of your work, and even on your final work product.
Work at a Natural Pace – This doesn’t mean “work slowly” as one might imagine, but really involves something I think about as working as an extension of your life. How do YOU work best? Should you spend more time putting the thing you’re working on down and thinking about it more? Do you work better if you spend time to kit up the parts you’re assembling (or build UML models of the code you’re building) first?
Obsess over Quality – I really like Cal’s point in the video that if one invests in quality tools (i.e., my Macbook that really makes me happy to code or write on) it’s a way for you to signal to yourself that your work is important and you ought to ensure you do the important parts as well as they have ever been done. He uses his grad school $50 lab notebook as a great example of this. How can one take lazy, incoherent notes in a really nice, expensive lab notebook (ostensibly with a very nice pen you’re proud of)??
My Fourth Category as Promised
Here’s Tod’s add. Maybe this is particularly me or maybe this is a pretty general thing, but here it is if it helps you.
4. Manage your Motivation: Your work productivity benefits (at perhaps an order of magnitude) when you are motivated to do it. For years I have pondered the difficulties and tricks for optimizing motivation cycles and have found that I do fabulously better work when I am “all in” on getting that work done. Sometimes, of course, one unfortunately doesn’t have the option of working on the “blue widget” when the motivation hits because the boss is impatient. But I’m going to guess that during those times, “blue widget” productivity and quality suffer significantly because they’re being worked on out out of obligation and not desire. Perhaps these times correlate strongly with surfing Reddit or YouTube?
It is also impractical if your ability to manage your motivation is weak and your motivation cycles are too sporadic. A cursory scan of my blog would probably reveal that I love to write (see my series on self-publishing). Unsurprisingly, I find that I write my most interesting and creative passages when the motivation to write hits, but I have also learned that I really need to create “commitment devices” to help ensure that I can channel that motivation into daily writing sessions. I imagine (or hope) that this is universal, as I have heard similar things from other writers or musicians.
Recap
Productivity in knowledge work is really hard to get one’s head around. It’s hard to define, difficult to measure (and automate measurement), and really challenging to normalize cost with the hours spent on the task. It feels like Cal Newport’s suggestions won’t necessarily resolve this difficulty, but it might allow the improvement of productivity — measurement aside — by focusing on the productivity of the most critical parts of the task.
image from https://www.mlb.com/glossary/rules/defensive-shift-limits
Abstract
in 2023 Major League Baseball made a rule restricting certain defensive players being in certain portions of the field (See here for the actual definition of the rule). This was done to combat “The Shift“, a defensive technique which was popularized by the Tampa Bay Rays in 2006, where one side of the field is overloaded with players.
I had the notion at the time that banning the Shift was just a band-aid measure and would have no impact. Since the ban was in 2023, we have had one full season to evaluate any impact of the ban.
History of The Shift
The idea of shifting players to counter power hitters’ tendencies to pull the ball to one side goes to the early parts of baseball. It disappeared for a long time, however, until Originally, the Rays’ had the idea on how to shut down David “Big Papi” Ortiz of the Boston Red Sox, a left handed hitter who had great power pulling the ball down the right side of the field. Joe Maddon, the manager of the Rays, used Sabermetrics to identify that Ortiz hit nearly every time to the right side, and mostly to the outfield. The ploy was effective and Ortiz, who had hit over .300 from 2004 to 2006 moved to .265 midway through the 2006 season after multiple teams started copying the Rays’ technique against him.
The Shift attracted a lot of fan attention because it was often deployed against the most well-known power hitters and was seen as stifling to the offensive aspect of the MLB. Eventually, it was banned (limited, actually, see the definition above for detail) and the 2023 season was the first to be held without the old, dramatic version of the Shift.
See below for an image of the Shift being applied by the Angels (there’s an extra person in the shortstop position).
Hypothesis
Image from Wikimedia Commons – By Jon Gudorf Photography – https://www.flickr.com/photos/jongudorf/16802945985/, CC BY-SA 2.0, https://commons.wikimedia.org/w/index.php?curid=112638138
Based on the way the Shift was deployed, I figured that if I wanted to demonstrate if the rule banning the Shift had any effect, I would have to evaluate the performance of elite power hitters both before and after the ban. This is not a perfect approach, though, because what if some other variable was introduced (a new “juicier” ball? Rules restricting pitchers) that impacted hitters’ performance. This means that I would have to evaluate performance differences of groups of “non-sluggers” as well to detect any non-Shift related performance changes.
I’m defining sluggers (the ones most impacted by the Shift) as hitters who have a Slugging Percentage (a common measure that records the total number of bases coming from hits) greater than the league’s average. My inclination is that the true sluggers are the ones who are at least one standard deviation above the mean (i.e., the top 16% of hitters.
Data Gathering
I used the Python library, pybaseball, to scrape some basic data. Pybaseball is useful in that it scrapes multiple baseball stats sites (including advanced pitch-based metrics). I only needed it to pull data on at-bats, hits, doubles, triples, home runs, and walks from 2006 to today’s date in 2024.
The data was pulled in two groups. One represented the “post-Shift” era from 2006 to 2022 and the other represented the “post-ban” era from 2023 to the current date. Data was evaluated by player and then normalized by the number of at bats. Multiple minimum at-bats were used (400, 600, 800) to determine impact of the Shift on players regardless of their usage on the team (but my insight was to not go much lower than 400 at-bats, in the theory that players who had few at-bats were unlikely to have the shift deployed against them (as it appeared to be reputational). Both groups were separated into two types of players, 1) “Normal” players, who’s Slugging Percentage numbers were close to the league mean and 2) “Sluggers”, who’s Slugging Percentage was a) in the top half of the league, b) one standard deviation from the mean (top 16%), c)_two standard deviations from the mean (top 5%), and c) three standard deviations from the mean (top ~1%). The notion is to identify if any of these groups of “sluggers” statistics (Hits, Doubles, Triples, Home Runs, Walks) were statistically different between the pre-Shift group and the post-Shift group.
Results
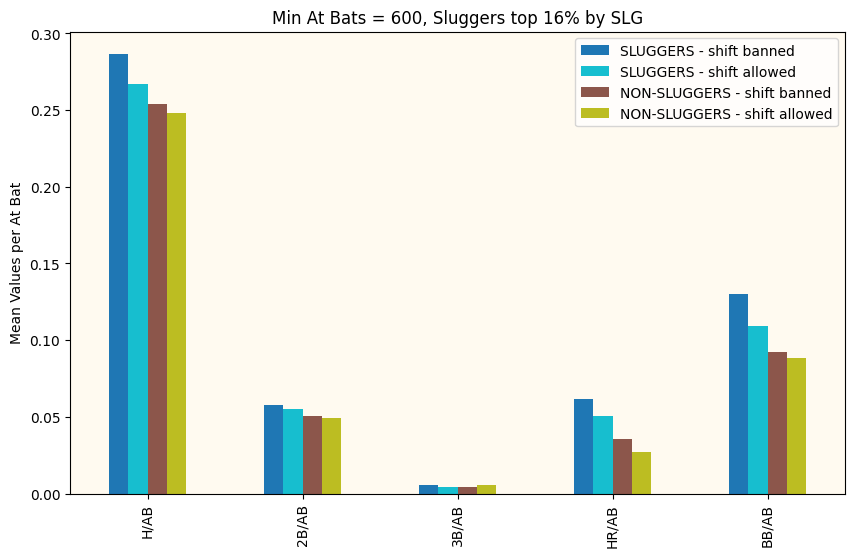
The first thing I looked at to compare performance from the “Shift Era” to the “Post-Shift Era” was the mean value of a number of common metrics. I selected ones that I felt were most likely to be impacted by the Shift. Hits, Doubles, Triples, Home Runs (the Shift doesn’t really impact Home Runs.. but I was curious), and Walks. I normalized these metrics by the number of at-bats for every player to make sure to keep things consistent.
Top 16% of Sluggers Compared Before and After the Shift was Banned. Also non-Sluggers for Comparison
I did this for a range of Minimum At Bats and Numbers of Standard Deviations away from the mean to define who was a “slugger”. They all looked a bit like this. The first thing I notice is that the period after the Shift was banned sees better offensive performance (and more walks) across the board. Great! We have an answer! No? Of course it’s never that simple. First off, we need to remember these are just the mean values for these eras and the mean of a distribution is not always the best way to describe the whole distribution. Also, we need to understand if these differences are significant or could just be explained away by common variation.
The next step was to apply an algorithm called the Kolmogorov-Smirnov two sample algorithm. This test compares the underlying continuous distributions F(x) and G(x) of two independent samples (pre-ban and post-ban) to determine if they come from the same distribution (our base assumption) or if they were drawn from different distributions. To wit, do the performance metrics before the Shift was banned have a fundamentally different distribution than the metrics after the ban. We will establish a required confidence interval of 95% (the typically accepted number) before we can determine the distributions different.
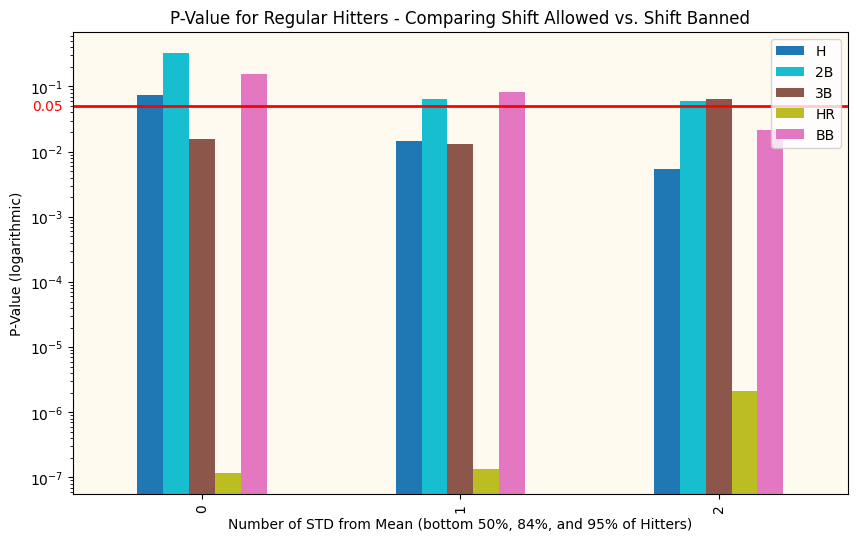
p-values comparing Sluggers before and after the ban. The red line is our confidence interval. Any bars below the red line indicate that metric is statistically different before and after the Shift
Above you can see the p-value for just Sluggers (top 50% of sluggers on the left, top 16% in the middle, and top 5% on the right) before and after the ban. We already know that the offensive metrics tend to be higher after the ban, this just tells us if that difference is significant and if it extends to the whole distribution.
p-values comparing non-sluggers before and after the ban. The red line is our confidence interval. Any bars below the red line indicate that metric is statistically different before and after the Shift
Analysis of the Results
There are obviously more charts, but these tell the story well enough. In the top chart (comparing Sluggers’ performance), we see that for the top 16% of sluggers, their performance on every metric other than doubles meets our requirements to claim that the differences are statistically significant. However, it’s hit or miss (pun!) for the other two clusters. Hmm.
Then looking at the non-slugger comparisons (we are comparing the hitters in the lower 50%, 84%, and 95%), we see that there are fundamental differences almost in all categories (most of the bars are below our red line, indicating that the performance changes in these metrics are significant), clearly more than with the sluggers! This indicates to me that something OTHER than the Shift has been responsible for affecting offensive performance across baseball. The Shift was rarely or never applied to any players other than pull-hitting sluggers, so it couldn’t be responsible for the performance changes we see in this bottom graph.
Conclusions
It seems pretty straightforward. Offensive performance has changed across the board between the time period from 2006-2022 and the time period from 2023 on. These are a large number of years, and lots of rule changes could have happened.
However, the changes in performance have been consistent across all hitters in MLB, not just the sluggers.
In actuality, the Sluggers seem to have had a less significant increase in performance than the non-Sluggers.
All of this makes me say that the performance impacts was from factors other than the banning of the Shift and that my initial hypothesis that the banning of the Shift had no impact is true.
In the previous discussion (Part 1) on the measures seen at a Baseball park, I covered the pitching metrics seen here fairly heavily. It is possible that hitting metrics are reasonably well-known in many places, but there is at least one here on the scoreboard that some explanation may be required.
The Triple Slash Line
Review of the “Familiar” hitting statistics would start with what is sometimes known as the “triple slash line“. This is simply three statistics that are frequently seen shown in order separated by slashes, like this: AVG/OBP/SLG. This refers to, in order, Batting Average, On-Base Percentage, and Slugging percentage. The Batting Average definition is the percentage of at-bats ending in a hit. An at-bat is defined as a plate appearance that ends in an out (excluding sacrifice flies), a hit, a fielder’s choice, or an error. For years, batting average was the preferred statistic for comparing player performance, but in recent years, the other metrics in the triple slash line have increased in prominence due to their impact on scores (and thus, wins). On-Base Percentage is more simply defined… it is the percentage of plate appearances where a batter reaches safely (could be a hit, walk, or getting hit by a pitch), excluding reaching by error, fielder’s choice, or a dropped third strike. This metric goes back to the Hall of Fame manager of the Brooklyn Dodgers, Branch Rickey, who is still beloved for his innovations in baseball (including signing the great Jackie Robinson and breaking baseball’s color barrier). One of the breakthroughs of the Oakland General Manager, Billy Beane, that became famous in the movie “Moneyball” was a stronger reliance on OBP when signing free agents. FInally, Slugging Percentage is a metric designed to give weight to a batter’s power. The formula is (#Singles + 2*#Doubles + 3*#Triples + 4*#Home Runs)/Plate Appearances. This makes slugging percentage useful, but not necessarily perfectly correlated with runs and therefore wins.
As an example of how the triple slash line can aid in evaluating player value, consider these two players (2024 stats as of 6/20/2024).
Aaron Judge (Center Field, NY Yankees): .303/.429/.697
William Contreras (Catcher, Milwaukee): .304/.364/.461
Though these two players (both having very nice seasons) have almost identical batting averages, that doesn’t tell the full story. Aaron Judge has batted in 66 runs this season whereas Contreras has only batted in 48 (on very similar numbers of games played). Judge has 27 home runs to Contreras’ 9. Amazingly, Judge has been walked 30 more times (57 to 27) than Contreras. Obviously this means that in walks alone, Judge has had 30 more scoring opportunities than Contreras. This has translated to Judge scoring 5 more runs this season. But this is at the cost of 20 more strikeouts for Judge. Lots to think about! First, let’s discuss the impact of RBI and HR to wins .
The RBI, short for Runs Batted in, has always been seen as a fairly critical metric in baseball, as it recognizes a hitter’s role in a run being scored for their team. It can result from a hit, a sacrifice fly, or even a walk, but not an error. In a sense it is a really valuable metric because it shows impact on the most important measure, the runs a team scores in a game. In another sense, one may over-reach when comparing players by their RBI accomplishments, because a player who is preceded in the batting order by a player with a stratospheric on-base percentage has a much higher chance of having a hit bat in a run. So RBI isn’t comparing apples and apples. There is a big controversy over the RBI metric amongst baseball nerds due to this. If you want to go deep down this rabbit hole, here is a good article from Bleacher Report back in 2012.
The appearance is that more home runs lead to a greater number of wins for one’s team. The home run (especially one that ends the game!) is exciting and draws fans more than anything else. The modern era of baseball is often referred to as the “Long Ball Era” due to the prevalence of home runs in the game. A method to identify the value of the home run called regression shows that home runs tend to be highly correlated with win percentages. Conceding that home runs are correlated with wins, the next question would be if home runs CAUSE wins. These are two very different things. Ice Cream sales are highly correlated with higher temperatures, but we cannot say that the temperatures cause the sales. The answer to the question about home runs causing wins is a hard one, and there are plenty of scientific papers analyzing this (and doctoral dissertations!). What seems obvious is that teams value the home run highly — even in the face of the higher numbers of strikeouts that power hitters tend to rack up. One thing that we know, though, is that teams express value through the salary they give a player. In this respect, Aaron Judge stands out with his $40M annual salary compared to the $760K that the Brewers are paying Mr. Contreras! (I think he’ll be getting a raise after this season!) Here’s where I found these salaries…
The Mystery Metric, OPS
All of this builds up to the final metric on the scoreboard that is less known, OPS. This stands for “On-base plus Slugging” and is actually a combination of two metrics from the triple slash, OBP and SLG. They’re just simply added together. I suppose this metric saves fans time (or the mathematical embarrassment) of adding the last two numbers in the triple slash together. The intent of the OPS is to provide a view into overall effectiveness of a hitter and their potential value for scoring runs. The historical record for OPS was rung up by Babe Ruth (1.16), followed closely by Ted Williams and Lou Gehrig. So clearly it is a measure of the historical greatness of a player. By the way, keep an eye on Aaron Judge’s OPS in 2024 (currently at 1.126), as he is threatening the Babe’s record!
In the modern era of more and more esoteric baseball metrics, how can one understand what the ballpark is telling us?
Scoreboard at Chase Field, Phoenix, AZ
This weekend I went to the Diamondbacks game at Chase Field, a treat I have enjoyed for a number of years. As a person who likes numbers, it struck me that the stadium was even more awash in statistics than ever. It brought a lot of questions to mind, some of which I’ll explore in this blog entry.
The Scoreboard, Explained
Much of this scoreboard layout looks fairly familiar to someone who may have looked at box scores or attended other big-time baseball games. The score by inning is something that has been featured for years. It tells us something interesting, the rate at which the two teams have been adding to their score. Knowing how pitching assignments work in major league baseball, one can quickly surmise that the White Sox starter got shelled early and seems to have stabilized a bit by the fourth inning. The Diamondbacks’ starter, however, seems to have pitched a fairly solid first four innings, because we can see that he has given up only three hits (less than one per inning). The White Sox scored one run off of him in the third inning, but we can also see that Arizona has one error. Did this error result in the one run? If so, that would be an unearned run and therefore wouldn’t be counted against the Diamondback pitcher’s Earned Run Average. We can see more about the White Sox pitcher, Drew Thorpe, because the scoreboard gives more info about active pitchers in the upper right (the D-Backs were batting when this image was taken). Drew hasn’t had such a good game to this point… in 3 innings he has given up 4 earned runs… that translates to an ERA of 12.0 at the moment. He has also given up five walks (BB) and six hits, which results in a WHIP (Walks and Hits per Innings Pitched) of 3.67. Additionally, his ratio of Strikes to total pitches (strikes plus balls) is 0.52, which is 0.1 lower than the MLB average. Top pitchers typically have numbers like .65, so clearly Drew is way behind the pace of the best pitchers here. All of these measures (WHIP, ERA, %strikes) are very bad for Mr. Thorpe’s year averages and we can get all of this from the scoreboard.
The metric FPS% refers to First Pitch Strike Percentage. The Major League Baseball average is 57% and we can see that Thorpe is sitting at 47%. This is a pretty interesting metric. Weinstein Baseball (here) tells us that “if a big league pitching staff improved their first pitch strike percentage from 57% to 80%, it would translate into 100 fewer runs allowed over the course of a season. That translates into 10 more big league wins.” So what the scoreboard is showing us here is that Drew Thorpe has a control issue today… He’s giving up a lot of walks (per Weinstein, “70% of walks start with first pitch balls”) and possibly in trying to get the ball over the plate “whatever it takes” he may also be giving up some easier pitches to hit.
One other metric regarding pitching that we can take away from the scoreboard here is “MVR”. This is placed just to the right of the Error (E) column. I actually had to Google this one during the game. It’s kind of new and stands for “Mound Visits Remaining”. So Mr. Thorpe has already had more than one mound visit during his first 3 innings and now only has two left. This is probably part of baseball’s desire to speed up the games and make them less tedious. The pitch clock is another similar effort, where there is only thirty seconds allowed between batters. ESPN tells us (here) that the pitch clock has reduced baseball games to an average of 2 hours and 40 minutes (24 minutes shorter) due to the pitch clock. This has also corresponded with a spike in batting average and stolen bases. It seems obvious that penalizing a pitcher by restricting their time between pitches is likely to reward hitters and base runners.
Pitch and Hit Exit Metrics
Another thing that I found very interesting is a display I had never seen before at the ballpark. See below.
I found that this was very distracting, because my brain wanted to identify the patterns of how they were classifying the Pitch Type. There were a number of different labels for pitch type, among these was “four seam fastball”, “cut fastball”, “slider”, “changeup”,”sinker”, “sweeper”, and “curve”. The “Vertical Break” and “Horizontal Break” numbers were very interesting. These data are captured by camera-based systems called Trackman or Hawkeye and are used across many different sports. There’s a great article in Baseball America (here) on how these pitch classifiers are able to label the pitch type. What I found is that the pitch types are calibrated to speed… a pitcher who threw a 100 mph four seam fastball also seemed to have their pitches in the 95 mph range that didn’t “rise” so much classified as a sinker. Whereas other, slower, pitchers may have had sinkers in the 80 mph range. Pretty interesting.
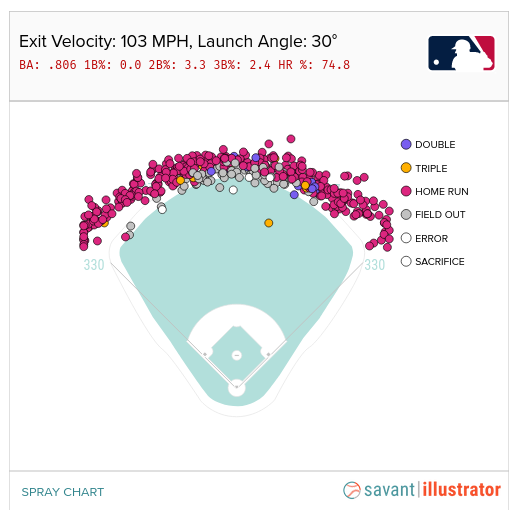
I also found myself looking after ball contact at the launch angle. A launch angle over 40% often indicated that a pitch that looked to the eye like a home run might actually just go to the warning track. Baseball Savant has a nice tool (here) where you can pick an exit velocity and a launch angle and see the actual outcome. For instance, below, 103 MPH exit velocity coupled with 30 degree launch angle was a Home Run 74% of the time!
Conclusion
Baseball parks have become inundated with information visualizations over the last few years. In some cases, advanced sensing and tracking systems like Hawkeye have enabled these new metrics to be collected. In others, new rules like the pitch clock and maximum numbers of mound visits have created demand for new metrics. But overall, baseball has always been a sport focused on its numbers, which is just one reason why many of us number people love it so much!