Abstract
in 2023 Major League Baseball made a rule restricting certain defensive players being in certain portions of the field (See here for the actual definition of the rule). This was done to combat “The Shift“, a defensive technique which was popularized by the Tampa Bay Rays in 2006, where one side of the field is overloaded with players.
I had the notion at the time that banning the Shift was just a band-aid measure and would have no impact. Since the ban was in 2023, we have had one full season to evaluate any impact of the ban.
History of The Shift
The idea of shifting players to counter power hitters’ tendencies to pull the ball to one side goes to the early parts of baseball. It disappeared for a long time, however, until Originally, the Rays’ had the idea on how to shut down David “Big Papi” Ortiz of the Boston Red Sox, a left handed hitter who had great power pulling the ball down the right side of the field. Joe Maddon, the manager of the Rays, used Sabermetrics to identify that Ortiz hit nearly every time to the right side, and mostly to the outfield. The ploy was effective and Ortiz, who had hit over .300 from 2004 to 2006 moved to .265 midway through the 2006 season after multiple teams started copying the Rays’ technique against him.
The Shift attracted a lot of fan attention because it was often deployed against the most well-known power hitters and was seen as stifling to the offensive aspect of the MLB. Eventually, it was banned (limited, actually, see the definition above for detail) and the 2023 season was the first to be held without the old, dramatic version of the Shift.
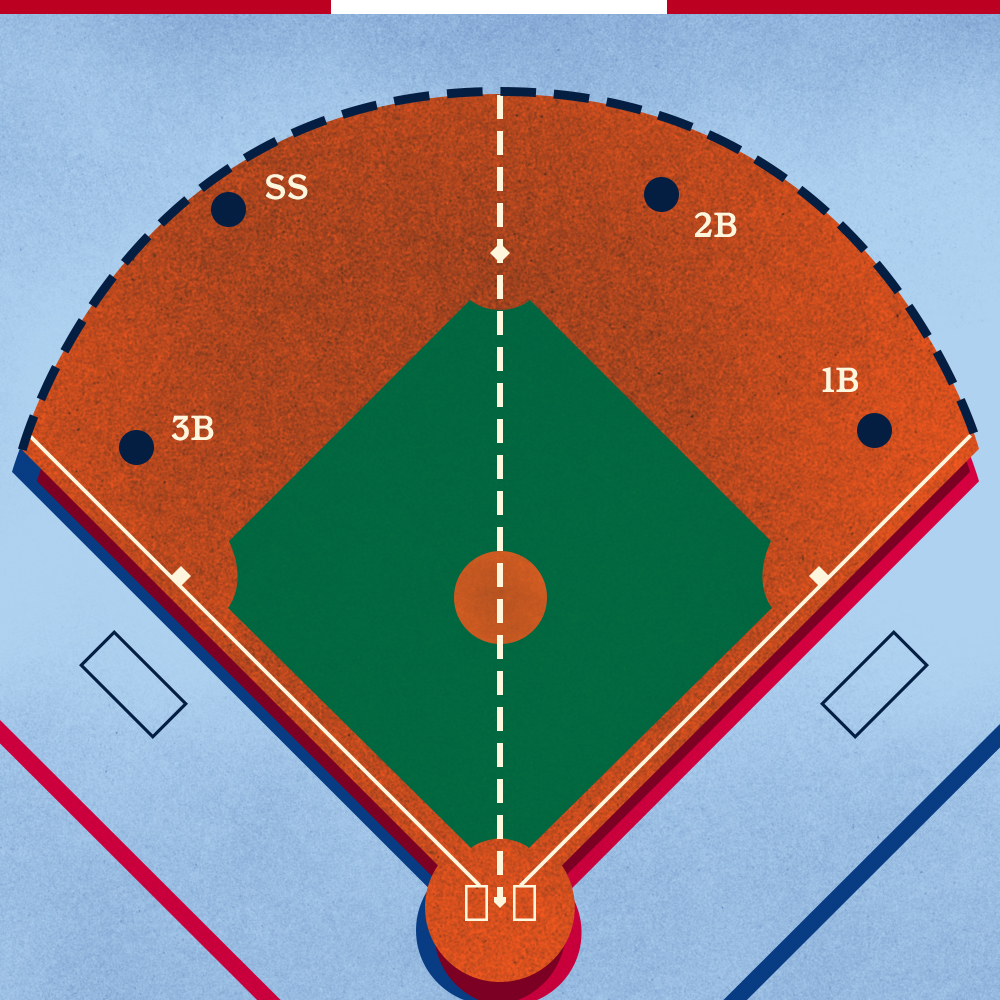
See below for an image of the Shift being applied by the Angels (there’s an extra person in the shortstop position).
Hypothesis

Based on the way the Shift was deployed, I figured that if I wanted to demonstrate if the rule banning the Shift had any effect, I would have to evaluate the performance of elite power hitters both before and after the ban. This is not a perfect approach, though, because what if some other variable was introduced (a new “juicier” ball? Rules restricting pitchers) that impacted hitters’ performance. This means that I would have to evaluate performance differences of groups of “non-sluggers” as well to detect any non-Shift related performance changes.
I’m defining sluggers (the ones most impacted by the Shift) as hitters who have a Slugging Percentage (a common measure that records the total number of bases coming from hits) greater than the league’s average. My inclination is that the true sluggers are the ones who are at least one standard deviation above the mean (i.e., the top 16% of hitters.
Data Gathering
I used the Python library, pybaseball, to scrape some basic data. Pybaseball is useful in that it scrapes multiple baseball stats sites (including advanced pitch-based metrics). I only needed it to pull data on at-bats, hits, doubles, triples, home runs, and walks from 2006 to today’s date in 2024.
The data was pulled in two groups. One represented the “post-Shift” era from 2006 to 2022 and the other represented the “post-ban” era from 2023 to the current date. Data was evaluated by player and then normalized by the number of at bats. Multiple minimum at-bats were used (400, 600, 800) to determine impact of the Shift on players regardless of their usage on the team (but my insight was to not go much lower than 400 at-bats, in the theory that players who had few at-bats were unlikely to have the shift deployed against them (as it appeared to be reputational). Both groups were separated into two types of players, 1) “Normal” players, who’s Slugging Percentage numbers were close to the league mean and 2) “Sluggers”, who’s Slugging Percentage was a) in the top half of the league, b) one standard deviation from the mean (top 16%), c)_two standard deviations from the mean (top 5%), and c) three standard deviations from the mean (top ~1%). The notion is to identify if any of these groups of “sluggers” statistics (Hits, Doubles, Triples, Home Runs, Walks) were statistically different between the pre-Shift group and the post-Shift group.
Results
The first thing I looked at to compare performance from the “Shift Era” to the “Post-Shift Era” was the mean value of a number of common metrics. I selected ones that I felt were most likely to be impacted by the Shift. Hits, Doubles, Triples, Home Runs (the Shift doesn’t really impact Home Runs.. but I was curious), and Walks. I normalized these metrics by the number of at-bats for every player to make sure to keep things consistent.
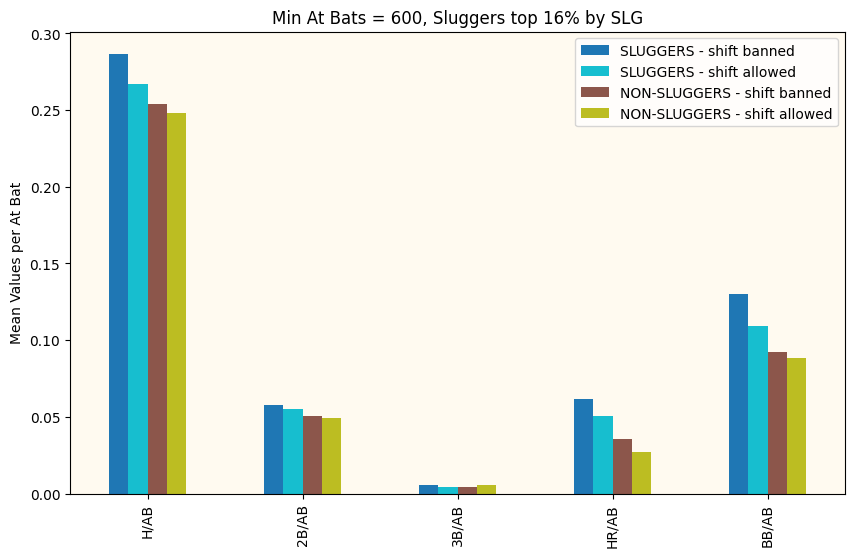
I did this for a range of Minimum At Bats and Numbers of Standard Deviations away from the mean to define who was a “slugger”. They all looked a bit like this. The first thing I notice is that the period after the Shift was banned sees better offensive performance (and more walks) across the board. Great! We have an answer! No? Of course it’s never that simple. First off, we need to remember these are just the mean values for these eras and the mean of a distribution is not always the best way to describe the whole distribution. Also, we need to understand if these differences are significant or could just be explained away by common variation.
The next step was to apply an algorithm called the Kolmogorov-Smirnov two sample algorithm. This test compares the underlying continuous distributions F(x) and G(x) of two independent samples (pre-ban and post-ban) to determine if they come from the same distribution (our base assumption) or if they were drawn from different distributions. To wit, do the performance metrics before the Shift was banned have a fundamentally different distribution than the metrics after the ban. We will establish a required confidence interval of 95% (the typically accepted number) before we can determine the distributions different.

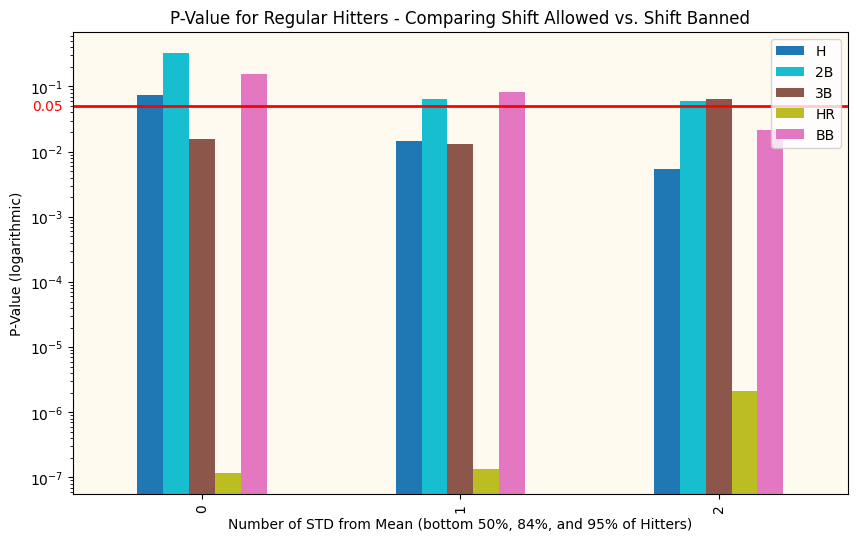
Above you can see the p-value for just Sluggers (top 50% of sluggers on the left, top 16% in the middle, and top 5% on the right) before and after the ban. We already know that the offensive metrics tend to be higher after the ban, this just tells us if that difference is significant and if it extends to the whole distribution.
Analysis of the Results
There are obviously more charts, but these tell the story well enough. In the top chart (comparing Sluggers’ performance), we see that for the top 16% of sluggers, their performance on every metric other than doubles meets our requirements to claim that the differences are statistically significant. However, it’s hit or miss (pun!) for the other two clusters. Hmm.
Then looking at the non-slugger comparisons (we are comparing the hitters in the lower 50%, 84%, and 95%), we see that there are fundamental differences almost in all categories (most of the bars are below our red line, indicating that the performance changes in these metrics are significant), clearly more than with the sluggers! This indicates to me that something OTHER than the Shift has been responsible for affecting offensive performance across baseball. The Shift was rarely or never applied to any players other than pull-hitting sluggers, so it couldn’t be responsible for the performance changes we see in this bottom graph.
Conclusions
- It seems pretty straightforward. Offensive performance has changed across the board between the time period from 2006-2022 and the time period from 2023 on. These are a large number of years, and lots of rule changes could have happened.
- However, the changes in performance have been consistent across all hitters in MLB, not just the sluggers.
- In actuality, the Sluggers seem to have had a less significant increase in performance than the non-Sluggers.
- All of this makes me say that the performance impacts was from factors other than the banning of the Shift and that my initial hypothesis that the banning of the Shift had no impact is true.
To see others of my recent sports analytic posts: