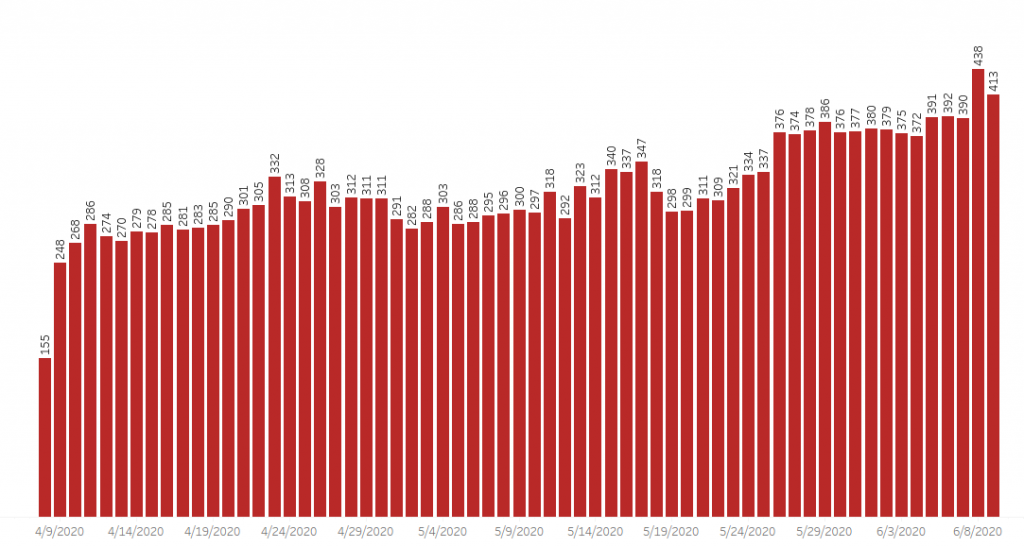
The chart above is the one I’ve been thinking about putting together for quite a while now. It’s really busy, but it has a ton of information in it. Here’s how to read it.
- Normalizing Case Counts by Population: I’m comparing both Pima and Maricopa counties (the two largest in the state by far) on a cases per 1000 basis. Why do I do this? If I compare them on raw numbers of cases, it looks like Pima County is doing SO much better than Maricopa because they have 1/4 the cases. However, Pima also has 1/4 the population. This is one way the news media exaggerates stories, probably because it looks stark and dramatic when you don’t compare appropriately. When I do this the right way, you can see that Pima and Maricopa had the same exact slope (more or less) up until Memorial Day. This is the purple arrow. After memorial day, we see case growth accelerate in both counties but a good deal faster in Maricopa County. This is the source of much of the overall case growth in Arizona.
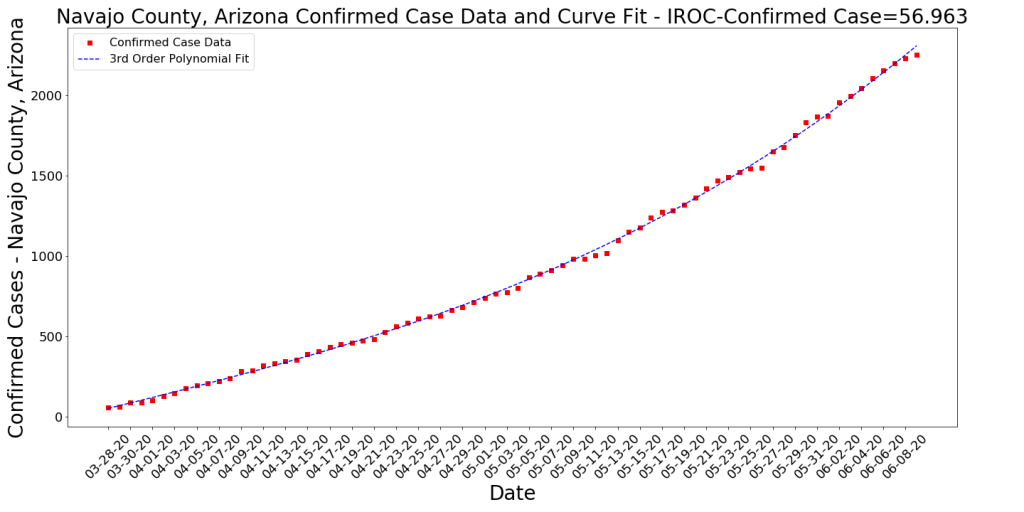
- Polynomial Trend Lines: The fat, light blue and pink lines are the trend lines for Maricopa and Pima respectfully. These are both modeled with 3rd Order Polynomials, which essentially means that the formula to create the trend line is something like Ax^3 + Bx^2 + Cx + D. This essentially shows that the case growth is accelerating (curving upward). Almost every state’s case growth right now can be modeled with this same kind of function. The trend line allows us to do simple predictions for the next few days on what the case growth might be. It is not a good predictor for much more than a few days out because the situation is too complex for that.
- Testing Numbers and Results: The yellow dashed line represents the numbers of tests on each day. I had to pull these numbers from the state’s online Dashboard manually because they won’t let us download it. So the data may be off by 5-10 tests per day. Note that the Test Numbers are represented on the secondary Y-axis (the one on the right). This can be confusing, but it allows me to provide more valuable visualizations. I also tried to capture the weekly percent positive for the tests. As you can see the percent of tests that are positive is growing. I’ll try to offer some possible explanations for that in my conclusion.
- Data Lags: Note that I extend the blue “Stay at Home” rectangle about 10 days past the 5/17 expiration date. I do this to demonstrate that most of the data we see every day has the potential for being as much as 10 days old. Data collection isn’t very clean and efficient when dealing with health-related issues. Any time you look at COVID-19 data, whether it is the CDC or the WHO or the AZ DHS, you need to remember that it’s likely reporting the state from a week or so beforehand. I’ve seen some embarrassing data analyses during this outbreak by professional media that did not account for the fact that recent data is likely to be underreported due to this lag. The testing numbers above are a good result. I have no reason to believe that AZ has slowed testing in the last week. We just don’t have the accurate numbers in yet.
- Events/Triggers: I’ve labeled various events and triggers on the chart. The stay at home order and its expiration are interesting, as is Memorial Day. Face Masks became mandatory in AZ on about 6/20. You can be sure that will be added as an important event as the time goes on and more data comes in. My expectation is that we’ll see some sort of change in the trends in late June or early July (to account for the data lag but also the 14 day hospitalization cycle time).
- Hospitalization: I’m not including hospitalization stats in this chart, largely because first, the chart is already too busy, but second, I have a hard time trusting/believing the states and counties hospitalization data, which all seem to contradict one another. Suffice it to be said that right now hospitals in the state are jam packed with COVID cases and there’s not much margin (at least in the traditional sense).
Analysis of the Chart
- Comparison of Pima and Maricopa Cases per 1000: As mentioned above, it’s very interesting to me that the case growth up until Memorial Day in both counties is essentially linear and basically the same slope. Ending the stay at home order doesn’t seem to have dramatically impacted this case growth rate (even considering the data lag). Two events seem to have occurred simultaneously that may be causal for the dramatic case growth lately. First is Memorial Day. We see the exponential case growth start a few days after Memorial Day. It may well be that a number of people contracted the virus during Memorial Day activities (we’ll probably never know if the protests/riots contributed due to bad data on those events). Maybe there were super-spreader events during the holiday too that we haven’t identified. The second major event that certainly contributes is the doubling of testing that also started about this same time. The state was conducting an average of about 8K tests per day up until about June 4th when it doubled this to an average of about 16K tests per day. During the stay at home period there was an extreme bias in the tests toward sick patients because one could barely get tested unless they exhibited symptoms. Even then, only about 5% of tests were positive. The spreading that may have occurred around Memorial day combined with the doubling of testing have resulted in not just doubling the number of cases, but exponential growth, because now the percent positive rates are approaching 20%.
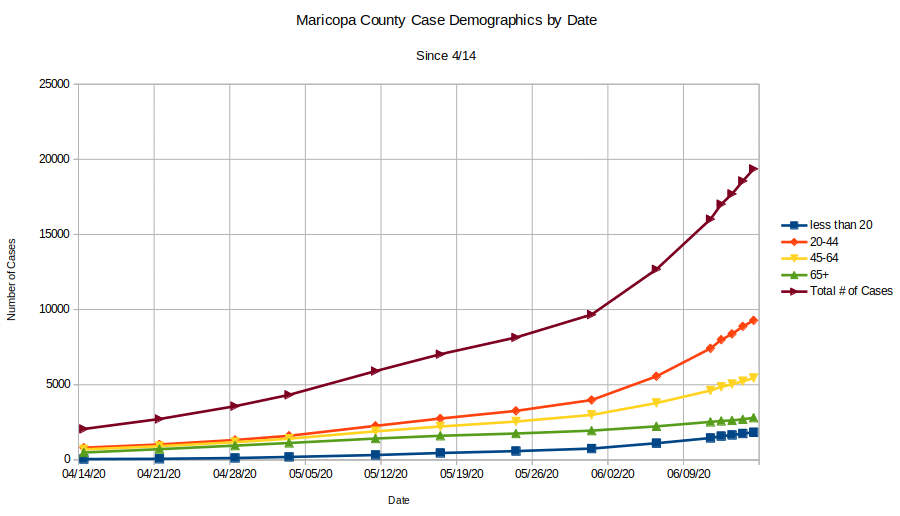
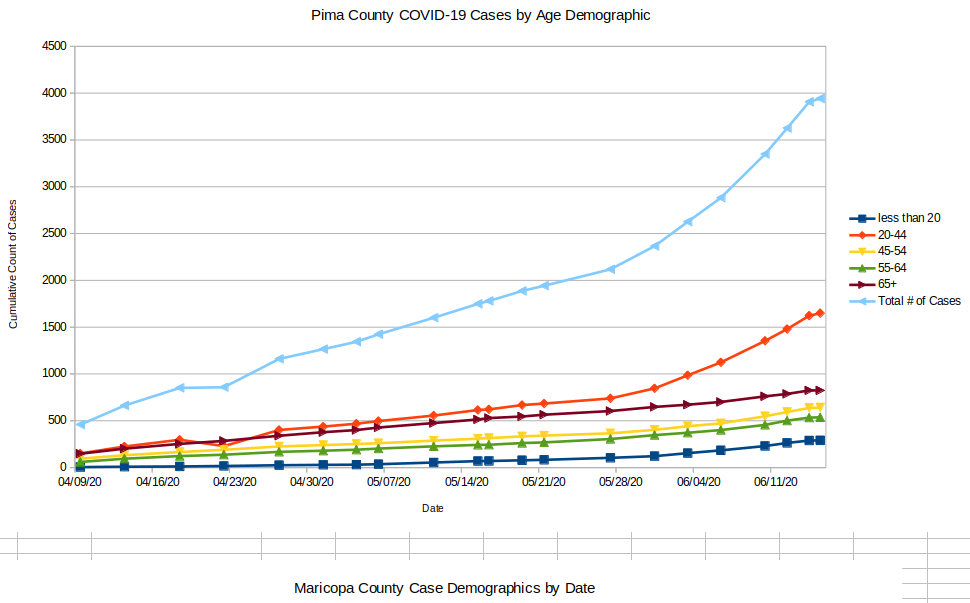
- Why are the Tests’ positivity rates so high? This is interesting to think about but here are a few possible reasons. First: There is a lot more virus out there now since Memorial Day and people are catching it. One telling stat is what I have shown a few times (which still holds) that shows that the growth rate of infections in the 65+ community is still the same now as it was during the stay at home order. In short, this demographic is still travelling down the same purple arrow! All other groups are reflecting the exponential growth trend. It is likely that the 65+ community is being just as careful now as they did during stay at home orders (and maybe group homes have also become more careful) and they’re avoiding the bloom in the virus. Everyone else is exposed to a larger population of the virus. This is speculation, but it makes sens. Second: It may well be that there is emerging another kind of testing bias and now people who are more likely to be infected are more likely to get tested. For instance, since I can’t see WHERE the tests are being conducted, there’s a chance that a higher percentage of tests are coming from regions that are already having major outbreaks (border counties, native communities). This is possible, especially given that there appears to be clear indications that the virus is more prevalent in some areas than others. The only way to really prevent this bias is to do what some European countries did and randomize testing. Otherwise we have no real idea of what’s happening. Third point: I’m convinced that we’re not seeing issues with false positives on the PCR tests (but I still believe there are high false positives on the antibody tests that make them somewhat less informational right now).
- Why are the Rates different for Pima and Maricopa County? First, one thing we’re seeing is that the rates can be very different in different regions. Not just across the world or across US states, but even by AZ Zip codes. After about 3 weeks of tracking this I’m still seeing the less wealthy zip codes have the highest overall numbers of cases per 1000 people AND the highest growth rates over time. This is interesting to analyze because it makes one curious about why this is happening. There are a number of hypotheses for this. It’s possible that people who are overall less healthy (maybe they don’t have good health care) may be more likely to get infected and then need to seek medical care. However, it does appear that this isn’t a very solid hypothesis when one looks at the demographics where the largest number of cases by far is in the younger, healthier age groups. Culture is one hypotheses I hear, for this, where the cultures in less wealthy regions have evolved to rely on others much more than the cultures in wealthy regions require. There are also ethnic cultures and traditions that may have some causality. Also, based on this evidence, some of the activities that are more commonly engaged in the wealthier zip codes (dining out, going to the gym, etc.) may actually be less causal of infections than we thought. From my observation, also, the culture of mask wearing in Arizona is stronger in the wealthier zip codes than in less wealthy or rural zip codes. It’s possible that this has an impact, but time will tell how significant of one. Regardless, there’s still much to learn about this.
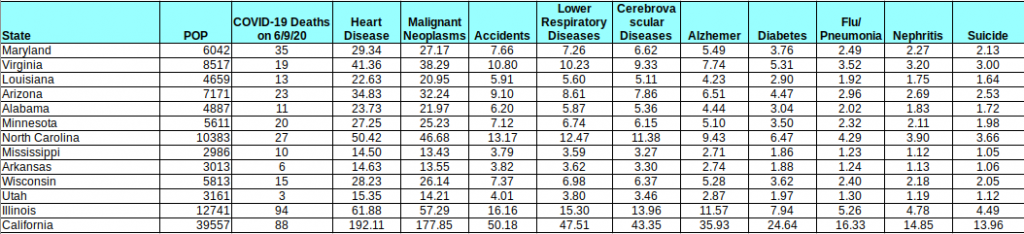
- Case Severity: With this virus, just like with the flu, there is a very wide range of severity. Measuring cases is interesting from a numbers standpoint, but it is not a good representation for the severity of an outbreak. A very large majority of the new cases we’ve been measuring (and in some cases, stressing about) are asymptomatic (or low-symptomatic) cases that aren’t requiring medical attention. The better measure of severity is deaths, of course, but also hospital cycle times and capacity measures (because they’re leading indicators for deaths). The hospital measures are extremely hard for a number of reasons mentioned in an earlier article on this site… Hospitals and their staffs are clearly being stressed with the growth in severe cases (even thought this growth is very small compared to the asymptomatic cases). Some of this is because this disease forces a 2-plus week cycle time on cases, something that appears to be extremely unusual for viral infections.
The Effect of Wealth on Cases in a Region

Above is the latest comparison of COVID-19 cases per 1000 population compared to median income. Note that the lowest median income zip codes is on the left and the highest is on the right. The average number of cases per 1000 for the poorest 25 zip codes is 9. The average for the wealthiest 25 zip codes is 2.6. You can see the yellow trend line shows a decrease in cases from the left to the right (case counts are on a logarithmic scale on the right y-axis). The red line are actual cases per 1K for the zip codes. Note that you may not see your zip code labeled on the chart (only about every 10th zip are labeled because otherwise the chart would extend around the room!).
Case growth follows this exact same trend. This means that the regions with the highest rate of change in their case counts (hot spots) tend to be on the left of this chart. This indicates that the overall trend of more cases in less weathy areas is not changing.
The Effect of Population Density

One explanation for the “wealth effect” is population density. This makes sense in light of the now-ubiquitous 6 Feet of Separation. Many of the lower income areas with high outbreaks are in zip codes that are known to have large numbers of people living in dense environments (apartment complexes, for instance). However, some of the regions with the highest outbreaks are rural and agricultural regions that have very low population density.
Overall, however, the chart above does show that the cases per 1K tends to go up as population density increases. The trend line is fit with an exponential function that has a decent (but not ideal) fit. Most likely, density is one component of the problem, but is likely not one of the larger components.
The Effect of Median Age

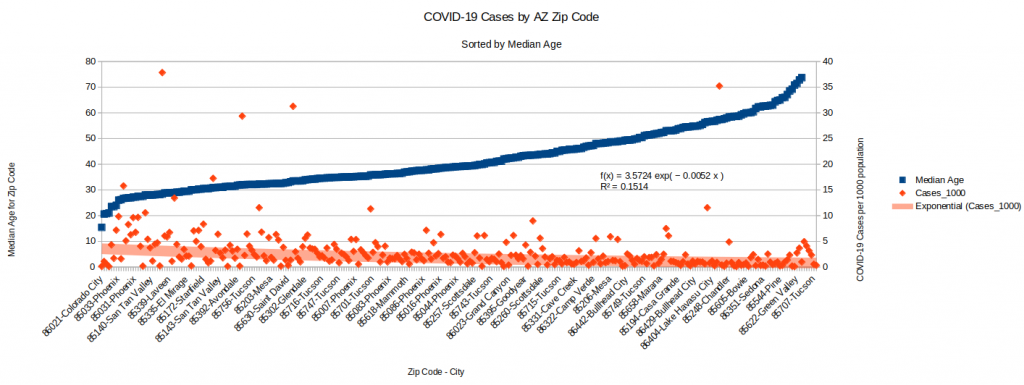
Another interesting characteristic of some zip codes that may be driving higher case counts is median age. This makes sense, especially since we already know that most of the cases in the current outbreak are asymptomatic cases among younger people. Therefore, this chart tells a very clear story. Outbreaks are much higher in regions with lower median ages.