I’ve been reading articles that have been getting published in the last few days on how the COVID-19 pandemic and the response to it was anywhere in between a hoax or at least an exaggeration, and all the way down to the end of civilization as we know it. Obviously there’s a lot of pent-up fear and frustration on the parts of different folks, but I can’t help but observe that every political side has been able to fit the available data to their position. I’ll try to provide the data and some history here that will help you make up your mind about these new conversations in the hopes that it will be useful.
First, there ARE a lot of deaths
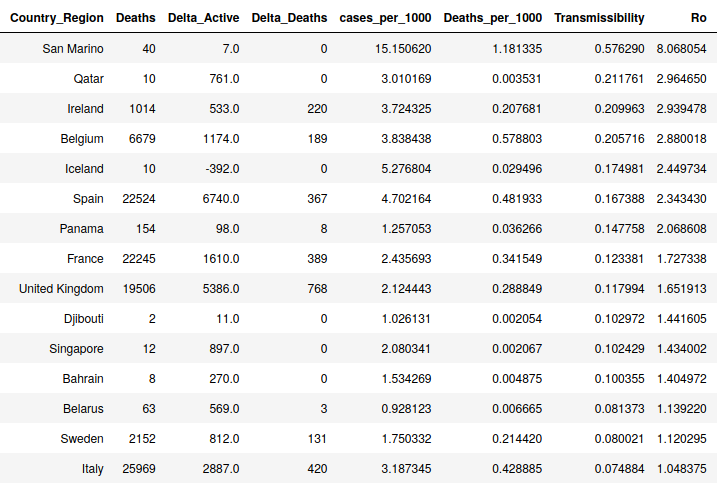
I continue to hear that this outbreak is no different than the seasonal influenza, but I’m not hearing much in the way of details as to why. Yes, in a bad flu year, we might have 60K deaths in the US. We have only had 2-3 months of COVID-19, though, and have hit the 60K mark yet have no idea how it will respond in the future. Additionally, COVID-19 has proved to have rates of reproduction (Ro) that were much higher than influenza (see here for my analysis of this). Really bad flu years (1968, 2009) have seen Ro values for influenza in the 1.5 to 1.8 range while normal years see around 1.2. Of course these are average numbers, but many countries are seeing Ro rates for COVID-19 STILL in the 1.5 range after the peak. Some regions are still seeing Ro between 2 and 3 even now, which implies that the numbers were higher before things started slowing down. The real peak Ro numbers are hard to pin down because we still aren’t totally sure exactly when the pandemic started. After this is all over the NIH will do a large statistical survey and will arrive at some numbers for incident and case fatalities, transmissability, etc., but right now, outside deaths, we just don’t have hard facts. Based off these high transmissability rates and the high death rates, however, it does appear that this outbreak is unique and all the evidence I have indicates it is worse than a bad round of the flu.
Right now there are 12 counties in the USA that have had more deaths in two to three months of 2020 classified as COVID-19 than they had in 2018 due to all diseases except heart disease and cancer. I’ll restate that. In two to three months of COVID-19 across a large number of counties, COVID-19 deaths have exceeded all 2018 deaths due to respiratory diseases, flu, alzheimers, etc. Plus, there are hundreds of counties who are close to this number. This rate may change, there may be no more deaths in 2020 due to COVID-19, etc. We have no idea. But at this point, this essentially means that due to COVID-19 at a minimum disease deaths in these counties will be doubled for 2020. You can see the numbers, it amounts to a few hundred to a few thousand extra deaths per county per year. This is very unusual due to one disease and if we see significant increases in other kinds of deaths like homicides and suicides, it becomes very newsworthy (Chicago). Will these deaths irrevocably change these counties? I suspect that is an exaggeration. But there will be an impact, not least of all psychologically. And of course the economic impact will also not be fully understood for months either.

Second, this does NOT seem to be like the Spanish Flu
The Spanish Flu was devastating to the world not just due to its large number of deaths, but in who it killed. I heard in a podcast featuring John Barry, who wrote the most important book about the Spanish Flu that the median age of those who died was 27. In some region, this meant that 3% of factory workers died from Spanish Flu. This obviously has far-reaching impact on a region’s productivity, their economy, the number of health care workers and first responders, etc., when people are cut down in their prime contributing ages. COVID-19 is not killing these people by anyone’s measure. The median age in most nations is somewhere around 80 and typically 85-90% of all deaths are over 65. This is not to say there is any difference in the value of lives at different ages (though I have seen recent articles that come close to saying this). But, there is a much more measurable impact on the society when individuals who are counted on to keep the economy running and people fed and cared for are suddenly removed. This is what the Spanish Flu did and what COVID-19 has not done to date.
One other thought on the Spanish Flu. It came in three waves, with the third one being the most devastating. Exposure to the first or second wave did not seem to provide immunity to the third wave.
Third, this DOES point to the Dangers of Society’s not Understanding Science and Statistics
I am not surprised when I see that a model has over-stated an effect. This is a known challenge of models. Most people who build simulations know that “All models are Wrong, but Some Provide Useful Information” and factor that in to decisions. But in society, this seems to be poorly understood, not just by the general public, but especially by politicians, influencers, and journalists. The public’s poor understanding of statistics was exploited repeatedly by news media on both political spectra. If we can’t improve our teaching of statistics at the high school and college levels, then we are probably not going to get out of this bad cycle. I strongly support reimagining how we structure math education in general (the Algebra-Geometry-Algebra II sandwich would be a good place to start).
However, scientists and modelers also need to better understand how to provide predictions to government and journalist groups in ways that are clearer and less likely of being misconstrued or misappropriated. I heard Dr. Chris Murray, director of the University of Washington’s well-respected Institute of Health Metrics and Evaluation (IHME) say on a Nate Silver podcast that the early COVID-19 models in the west were based on Hubei Province data. I think it’s pretty clear by now that Hubei Province data was created by local politicians and did not accurately measure the truth on the ground. So the most important part of that model was fit on data we now know was at best heavily filtered by a Chinese provincial government. I don’t think this was even known outside IHME until recently. My point is that in general, scientists understand the usefulness of their models but struggle to communicate a model’s limitations to a politician or journalist. This is, in a sense, a failing of science to understand how the rest of the world works. This may have gotten us into trouble during the early days of COVID-19, but perhaps there was some willfulness to understand simulation results in the context of a pre-existing bias by leaders and journalists.