I was looking at COVID-19 data that was sorted by case count and noticed that the Dakotas and Wisconsin were at the top of the list and then looked a column over and realized that all those regions still had low deaths per 1000 people. It made me curious about how common it is to have a high-deaths region.
So I built a histogram of all the counties in the U.S. and binned them by their deaths per 1000 persons. Just as a reminder, the height of the bar represents the number of counties in the bin. For instance, the tall bar on the far left represents about 500 counties all of which have less than about 0.1 deaths per 1000 persons. The really short bars on the far right represent the one or two counties with over 3.0 deaths per 1000 persons (0.3%).
I put labels on the histogram to identify which bars well-known counties fall in (yes, it’s biased towards Arizona).
Yes, the NYC boroughs (Queens, Bronx, Manhattan) all are still at the top of the list, but their death rates have slowed significantly from the peak rates back in March/April.
Also, the red line represents the exponential function that fits the decay of the histogram. Therefore, the likelihood of a county having a large death rate follows an exponential decay. The formula would be DECAY RATE = 432*e^(-2.5) + 4.3
Back in August I did my first detailed Excess Deaths assessment (See Link) based on data from CDC’s “Wonder” database on deaths from 2017 and 2018 and comparing it to data from the CDC’s provisional COVID-19 death counts (Link). Using this data I was able to measure data by state and by 10 year age demographic. What I found was interesting. To summarize, there were significant excess deaths in the groups that wouldn’t be surprising to you (65+ years old, Northeastern states and DC). But the really interesting (and concerning!) thing I discovered was that there were significant excess deaths in younger demographics who had been lightly impacted by COVID-19.
Quick Explanation of Methodology
The CDC Wonder Database allows one to search for total deaths by all types. The data is very detailed but it isn’t recent. In general the newest data in Wonder is 2 years old. Knowing that 2017 was a “high death” year due to large numbers of flu deaths and that 2018 was a bit below average, I decided to take these two years and average the deaths as my baseline to compare to 2020 data. The data from Wonder can be aggregated across regions (I chose States) as well as by demographics (I chose age in 10 year groupings).
The 2020 provisional death data put out by the CDC can also be grouped in similar ways (states and 10 year groupings). Plus, in addition to providing COVID-19, Influenza, and Pneumonia deaths, it also provides total death numbers for these groupings. This allows for an easy comparison. It is unclear how CDC arrives at these numbers, but they don’t seem to be extremely laggy and they line up more or less with the numbers from Johns Hopkins. Here’s a picture of the website where you can pull the data. As you can see, the claim from the CDC is that the data is as of 10/14.
Since the year is still not over, I’m doing a very simple scaling assuming that the death rate will continue at the current rate for the rest of the year. This isn’t a solid assumption, but I don’t think it matters much. Since we’re in October, 10 months along, I used a scaling factor of 1.2. Back in August (when the data was lagging a bit) I used a scaling factor of just under 2, accounting for 7 months of data.
Excess death percentages in the over 65 age population had decreased quite a bit. There were numerous states where this population had over 150% excess deaths but in the current results, I onnly see two older age demographics in the top ten. Note that since we’re comparing 2020 COVID/Flu/Pneumonia deaths with overall 2017-18 averages for each age group, this accounts for cases where total death numbers for older demographics are much larger than death numbers for younger demographics.
Excess deaths for younger demographics, particularly 25-34 and 35-44, have remained the same. This implies to me that the rate of overall excess deaths for these groups has stayed consistent while the rate of excess deaths for the older generation has fallen significantly. This is not surprising to anyone who has watched the data because it’s clear that even while COVID cases rise and fall, COVID deaths have been falling everywhere (for lots of good reasons). BUT, whatever is killing the younger demographic at higher rates than normal years has yet to slow down.
Overall COVID/Flu/Pneumonia Deaths as a percent of 2017-18 averages has fallen since August. This also aligns with the sharp decrease in COVID deaths since July/August.
Washington DC seems to have excess deaths across all age demographics. Note that the 5-14 year group’s 250% excess death number is only like 5 excess deaths… I’m not sure I could make a good guess as to why DC’s numbers are so high. Maybe someone can weigh in on this?
You can see the data yourself in the table below (sorted by 2020 excess death percentage). Yellow indicates a state/demographic pair that has low COVID/flu/pneumonia impact (around 15% or less) but still has high excess deaths
Merged Table of CDC 2017-18 average numbers compared to CDC Provisional 2020 death numbers. 10/20/2020
I also showed an overall histogram of excess deaths in my last post. This histogram is a type of chart that measures “counts” of samples that fit into a specific bin. For instance, in this case, each sample is a state/demographic pair and the histogram is plotted over 80 bins that range from around 10% of 2017-18 deaths up to around 150% of 2017-18 deaths. So each bin represents roughly 2%. We can see in this histogram that the peak of the histogram is where about 60 state/demo pairs fell into a bin that looks like around 90%. If you see this as the mean and the histogram as a rough bell curve (normal distribution) then you can see that using this method and based upon the CDC’s 2020 death projection numbers, the overall excess death distribution for 2020 has shifted to the left since August (when the peak value was in the bin that represented 110% (go back and look… don’t take my word for it!). This also makes sense knowing that the high death rates from April through June have slowed.
Combined age groups’ histogram of 2020 excess deaths – October 20, 2020
Since I was curious, I wrote code to plot the histograms for each age demographic to see how they related to each other. It’s a bit messy, but you can see in the legend which colors correspond to which demographic. Key takeaways from this visualization is that 1) 35-44 has been hardest hit, followed by 25-34, at least on an excess death percentage basis, 2) 65-74 seems to be slightly below the 100% which would represent the 2017-18 average, and 3) 5-14 and 15-24 have less excess death than 2017-18.
Overlapping Histograms for Each Age Demographic.
Highly Reported-on CDC Excess Death Pre-print (from 10/20) – take it with a grain of sand.
On October 20th a CDC scientist released a pre-print that the CDC published here. The assessment of the authors, based upon their simulation is that there were 299K excess deaths in the US during 2020. Of course, this was immediately picked up upon by our fearless media. In many cases, they reported on the pre-print incorrectly because the statistics in the pre-print go a bit beyond that of a newspaper data scientist. Actually, the statistics in the pre-print are a bit muddy and don’t seem to line up in places, so I can’t blame the news journalist folks much. I might write a longer report on this paper if I get time, but I’m not confident in their simulation’s assumptions on a typical year-to-year death growth rate and they don’t account for deaths that didn’t occur because a sick person died of COVID first. And their overall numbers don’t match the ones that CDC publishes in the provisional 2020 death numbers either, so this is problematic. I took a stab at replicating their model based on a much simpler and more reasonable regression model than what they selected and their 299,000 number (compared to the 2015-2019 average) appears to represent expected growth in deaths, not excess deaths (see chart after conclusions). We’ll have to wait for the actual paper to come out with all the details I guess. Of course, the Washington Post didn’t wait..
Conclusions
It is tough to make any solid projections based on ANY COVID-19 data. It is always possible that the CDC’s data is inaccurate (it usually is… these kinds of things are infamously hard to measure). And clearly 2020 is a unique year for deaths. It isn’t clear from the CDC’s data that COVID-19 has created significant excess deaths, however.
The really serious question is about the real excess deaths that haven’t slowed down in the younger demographics. This problem is not coming from deaths due to COVID but is likely related to the anxiety and stress created by COVID, by government actions that are aimed at reducing or eliminating COVID cases, by isolation, etc. Unfortunately there is a lot of evidence coming out that these governmental actions haven’t been exceptionally effective (a quick look at COVID case rates across various new government actions shows that they haven’t had very measurable impacts). The other takeaway is that excess deaths for ages younger than 15 have been much less than 2017-18 averages. The combination of being isolated from society (driving in cars less, less exposure to disease, etc.) and the lack of an effect on this group from COVID are likely the cause.
Backup: Tod’s “Simpler” 2020 excess death model
Deaths per 100K persons since 2012. Note this is normalized by population, but despite this, deaths have been increasing consistently for the last 10 years or so. The Red Dot is the regression-based projection of 2020 deaths. Note that the delta of about 60 deaths per 100K between 2020 and the 2015-2019 average will amount to around 295K “excess deaths”.
As temperatures fall in different parts of the US, we’re starting to see case growth acceleration resume in some of the hardest-hit regions from the spring.
US State COVID-19 Data Table sorted by Case Acceleration (dIROC_confirmed) – 10/7/2020
Below we can see the table sorted by the acceleration of the death rate. These are pretty much the only states that are seeing increases of the rate.
US State COVID-19 Data Table sorted by Death Rate Acceleration (dIROC_confirmed) – 10/7/2020
Since New York seems to be re-emerging here with above average increases in the Case Rate and Death Rate, here’s their time series plots below, first Case Rate and then Death Rate. The Instantaneous Rate of Change for cases (IROC-Confirmed) is around 1000 new cases per day. For deaths the IROC is about 20 new deaths per day. Both of these values are growing. You can visibly see the Case rate increasing (the cumulative case line is curving upward) but the Death rate increase is a bit too small still to visualize well (but you can see the polynomial fit starting to show the upward curve).
New York state Cumulative Case curve plus 3rd order polynomial fit. 10/7/2020New York state Cumulative Death curve plus curve fit. 10/7/2020
Top Twenty AZ Zip Codes by COVID-19 Case Growth, 9/11 to 9/18 – data source: AZDHS DashboardTable: All AZ Zip Codes with over 6% Case Growth between 9/11 and 9/18 – data source: AZDHS Dashboard
Evaluation of Case Growth Over the Last Week
I notice a handful of interesting things in the data this week.
University of Arizona cases APPEAR to have shot through the roof. Note that 85719 has most of the U of A population (see how big the zip code is?) and it appears to have a very large majority of the University-related COVID growth. The next highest zip codes in Pima County are residential zip codes from suburbs such as Oro Valley, Marana, and Green Valley and the growth percentage is based off of very small numbers of cases. These would all be very long commutes for an on-campus student. 85705 is the zip code just north of campus and it saw an 8% increase in cases, which is interesting, because I’m curious if U of A cases will start spreading to adjacent zip codes. But the 100 cases that make up this 8% growth is far smaller than the number we see in 85719 over the last week. Will continue watching this zip code to determine if the University outbreak is spreading. There’s a good chance this is just measuring COVID-positive students that are living off-campus in large complexes.
The 85719 Case Growth captured by the state seems much too high based off of the number the University is releasing from their new dashboard. It’s not clear how numbers get from the University to the State, but I can’t see much consistency to date. More on this later in this post.
I notice that Case Growth in Flagstaff (Northern Arizona University) has increased. The raw number is ~100 new cases, but this is based on a small number of cases to date. Last week we didn’t have many new cases from this zip code.
I also notice that ASU’s main campus in Tempe doesn’t even factor in the top 20 any longer. I look at their numbers and see an increase of only about 20 cases. This combined with the official ASU reporting (here) makes very little sense. I’ll analyze this later in this post too.
The 85709 zip code in the southwest corner of Phoenix continues to see large case growth. This zip code has seen a lot of cases and was frequently one of the hottest COVID spots during the June-August phase in the outbreak where case growth was the largest. Back then, there was evidence that the outbreak in this zip code was correlated with the similarly large outbreak in Sonora, Mexico, but this may not be the case now. It doesn’t seem obvious that this growth has any correlation with the university cases either. I can’t see case demographics by zip code, but I do know that the age demographic under age 44 accounted for 64% of the Case Growth in all of Maricopa County. Since 85709 has a median age of 28, there’s a good chance that over 64% of the new cases in this Zip code are under 44. I still feel that this is interesting and ought to be evaluated.
The Challenges of Understanding Case Growth Accurately
The confusing nature of the latest data from the state is something worthwhile to discuss because I’ve noted news outlets (tucson.com is terrible about this for instance) grabbing the latest U of A numbers, interviewing one U of A professor, and then writing a very scary but highly inaccurate article. It’s even worse now since the numbers are smaller and therefore plagued much more by statistical variation. So here are some thoughts about our current state of counting cases to help you understand what might be really happening.
It is Difficult to Use Data that is Generated “by Accident” to Learn Big Things. In an application of data science within a field like epidemiology we often want to draw an inference from a selection of measured data that applies to a broad population. This is usually done by sampling a representative portion of the population to the overall population we want to understand. Just like conducting an election poll, this kind of representative sampling needs to be well-designed and well-measured. The collection of COVID-19 has come about “by accident” and thus has nothing in common with a well-architected election poll. This means we can truly extract very little inference about specific aspects of this outbreak from the data samples that come into the state DHS dataset. Due to the nature of collection of data in an emergency (without any pre-formed strategy, of course) we get what we get and if we’re lucky we can determine if any natural experiments can be uncovered in the data. Just keep this in mind and it will help. 🙂
The University of Arizona Appears to be Relying too Much on an Inaccurate Form of Testing. The data sampling strategy at the U of A and apparently at the AZDHS has changed since school resumed on campus. U of A built their dashboard and this clarified some of their strategy but also revealed some real gaps. What does their strategy appear to be? Conduct low-cost Antigen tests that provide results in real time whenever there’s any evidence of a localized outbreak. This makes good sense based upon the apparent limitation of the Antigen tests (see point #x). Isolate the people with positive results and conduct more-accurate (but slowly scored) PCR tests on the symptomatic (or on football players with positive Antigen tests…). We know the numbers of Antigen tests vs. PCR tests (about 10 Antigen tests to every PCR test) and the numbers of tests conducted by Campus Health to those conducted elsewhere (10% of tests are being done at Campus Health). This seems to indicate that 10% of the U of A positive COVID cases have symptoms deemed worthy of a visit to the nurse. The upside is that this seems to be a pretty solid approach. The downside seems to be that the positive Antigen tests (about 1/2 of which are likely to be false positives) are getting inconsistently sucked into the AZ DHS case data. The reason I struggle with this is that the quality of the Antigen results is highly variable and likely to be wrong. This also drives more chicken little journalism. In my mind the only valuable positivity numbers are coming from the PCR tests being conducted at the health clinic. These will isolate the positive cases with symptoms (but will likely miss the much larger numbers of students that get COVID without symptoms). Unfortunately, the state seems to be recording all the positive numbers, including the many false positives.
Yet Again, Arizona’s DHS Has Changed their Measurement Strategy in Mid-Stream. AZDHS has changed their collection strategy. My points above about these Antigen tests being less useful for serious data collection have kept results from these tests out of the AZDHS data up until this week. I noticed on their dashboard that they changed the name of a category from “PCR Tests” to “Diagnostic Tests”. This, combined with the large increase in tests at the same time makes it clear to me that they’re now equating PCR and Antigen testing and pulling in the Antigen test results from the U of A and elsewhere. My experience is that it is NEVER good to change your data collection strategy in mid-experiment. Now all the new test data is contaminated and will be statistically different than the first few months of data collection. What they should have done is added a third category of testing. Then they could report on PCR Tests (the gold standard), Antigen Tests (less accurate but valuable for speed), and Serology Tests (for antibodies). The willingness by AZDHS to change measurement strategies in the middle of a health care crisis continues to surprise me (no, this is not the first time).
Arizona State’s COVID Stats are Not Very Transparent. ASU seems to not have a very solid collection strategy and their numbers make very little sense. Their numbers are surely not decreasing, but that’s what they seem to be advertising. They describe a decrease of around 120 cases in three days from their Tempe campus. This seems very strange considering that U of A is showing case growth at U of A of around 500 during that same time frame (this is both PCR and Antigen test numbers). Clearly the two Universities are not measuring the same way.
The State DHS Numbers Don’t Seem Accurate for the Primary U of A zip code. The 85719 numbers from the AZDHS site showing growth of about 1400 cases in the last week seems out of line compared to the 890 cases (PCR+Antigen) the U of A reports. Only about 200 of those cases are based on PCR test results. This is further evidence that AZDHS has now started recording positive Antigen tests. This is another data measurement mistake. For the first X months of COVID all our results are based off PCR tests which have very few false positives. Now we’re adding a low-quality source of data to the high quality one and we can’t separate them. Most likely this number is erroneous and I suspect that the confusion in changing the method that the state records cases may be partially to be blame. I’d guess some accidental double counting is happening in this confusion.
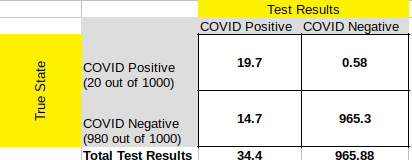
COVID Antigen Testing False Positives make the Test Less Meaningful: I’m disparaging Antigen tests a bit here. These tests have been used for years in other diseases to identify key proteins that will signify the presence of a viral infection. COVID-specific Antigen tests have been recently approved in emergency fashion by the FDA. In their interim guidance, the CDC says that Antigen tests have very low false positives, but the manufacturers indicate something different for their COVID Antigen tests. One of the main ones out there now is made by Abbot, who generally has some of the most accurate tests across the board. The Abbot press release from a month ago indicates a sensitivity of 97.1 and specificity (false positive rate) of 98.5. Assuming this is a reasonable representation of other Antigen tests that have been approved, it will more-than-likely result in 1/2 of the positive tests being false. Here’s how that works:
Confusion Matrix for the case where we conduct 1000 tests in a population where 2% is infected (very realistic numbers for COVID-19 at a given period of time) with a test that has 97.1% sensitivity and 98.5% specificity.
See the confusion matrix above for the case referenced. Right now 2% infection is a high estimate for just about any community we might sample (Arizona State is indicating that 0.4% of their student population is infected right now). If this number is truly lower, we see a case where nearly every positive result is false. If you take a moment to digest the diagram, you’ll note that the false negatives are very low (the upper right quadrant) where the false positives are about 1/2 of the total positives (lower left quadrant). This is why when a disease is rare (like COVID is — despite all the headlines) sensitivity is relatively meaningless while specificity is critical. The Abbot Antigen test’s specificity of 98.5 sounds great, but in a rare event, it really means that 1.5% of all the people who don’t have the disease (in our case 980 out of 1000) will show up as positive. When we only expect a small number of true positive results (in our case, 2% of 1000, or 20) then the false positives drown out the signal from the true positive. About 1/2 of the people who are told they have COVID in this example actually do not. Hopefully this helps make my case that the state should NOT be including Antigen test results with PCR test results (which since they use DNA/RNA testing to evaluate the presence of the virus have very close to 100% specificity).
Now if you target these Antigen tests in a more focused way, i.e., on a Sorority where you believe a population exists that has a much larger infection rate, then the test will be much more accurate at determining exactly who is infected. This is because there are less “well” people to inflate the false positive count. If the True positives are just twice the number of false positives, the test is now much more useful at evaluating who the sick people really are. BUT, if you deploy it broadly into your broader community the way the U of A is, with thousands of tests per day, the false positives will overwhelm the true positives.
Arizona has seen its case growth numbers head towards zero for the last few weeks, but there may still be some value in exploring how the infection is affecting the state. Remember, tracking COVID cases is not useful in itself. Cases are a strong leading indicator, of course, of things we structurally care about as a state, such as hospital overtaxing and ultimately deaths. I believe this is the most productive mindset to have when approaching cases. Here is what the state’s cumulative Case curve looks like now.
AZ cumulative Cases, 9/11/2
We note that the Instantaneous Rate of Change (IROC) of the curve has now dropped to somewhere around 790. The trend is decreasing, however, as you can note about 4 days in a row where the rate appears to be approaching zero. We have three to four days of anomalous data from about 9/2 to 9/4, where the state appears to have been capturing University Antigen tests as confirmed cases. As the U of Arizona learned, at least, many of these Antigen positive results have turned out to be false positives when checked with a subsequent, more accurate PCR test. It appears from the data that 60-70 percent of the Antigen positive results are false positive. Since this realization, the state appears to only be counting the university cases if they’re confirmed with a PCR test. But not doing this for 3 days or so appears to have inflated our case numbers. Enough on that.
Zip Code Case Growth Update
Top Thirty Zip Codes by Increase in COVID-19 Cases from 9/5 to 9/11
This map doesn’t look much different than the previous week’s case increase map, except that there appears to be a bit higher numbers in Flagstaff (home of Northern Arizona University) and Prescott (home of Embry-Riddle University). But by far, the top two zip codes in case growth over the last week continue to be the homes of the University of Arizona and Arizona State. This is true even though the numbers of cases reported have dropped a bit due to only recording the cases confirmed with PCR.
Table of Zip Codes
Top 12 Zip Codes by Case Growth, 9/5 to 9/11
The main thing to note here is that the top two are Tempe’s and Tucson’s University zip codes. Snowflake’s showing up as number three is a bit deceptive. They had 11 new cases this week, but they’ve only had 128 cases to date before this week. The 11 might be from one significant spreading event, or it could just be random noise. The 85009 zip code in Southwest Phoenix has been one that has had a handful of case spikes since Memorial day. The 200-ish new cases in that Zip code could be significant, especially since the Mexico-related infections from a month or two ago seem to have slowed significantly.
Conclusion
Data indicates that COVID-19 might be in the process of burning itself out in Arizona. For now at least… It will be interesting to see if the University cases lead to increased hospitalization numbers in their demographic about a week from now (so far, there hasn’t been any change). With this Zip Code approach above, we can also track if the University cases are spreading to adjacent or other Zip Codes.
Below you’ll see the Arizona Zip Code map of Case growth in the last week. Color of the bubbles represents the % growth in cases over one week. Size of the bubble represents population size of the zip code. What do we see?
1. We see two zip codes with growth far greater than any others. 85719 (U of Arizona) and 85281 (ASU) come in at 38% and 23% growth in cases over the last week. The next highest zip code is in Buckeye and comes in at 7.3% growth.
2. Flagstaff comes in around 4.3% growth. Perhaps they party less at NAU, or maybe there are less cases at altitude?
3. The below map only shows the top 30 zip codes. Most of these are under 5% growth.
4. Right now I’m doing this to see if the university cases spread outside the university areas. My hypothesis is that they will remain contained and the infection will burn itself out in those zip codes. I’ll be watching this and publishing results about every week. I’m also watching the hospital stats closely to see if the university case growth will result in increases in hospitalization.
Arizona map of top 30 zip codes by case growth between 8/30 and 9/5/2020Table showing top 18 zip codes by case growth between 8/30 and 9/5 and some info about each zip code
UPDATE
Apparently, it turns out that some of the numbers from the Antigen tests have been false positives. The U of A admitted this and in doing so, it became clear that positive Antigen tests are going to the university health center to take PCR tests to confirm. Initially, the state was counting all of the Antigen positive tests as positives overall, but that seems to have stopped. Recall my earlier discussions about specificity and false positives. Any time a test has a specificity of around 97 or 98% and the disease is infecting only about 2-3% of the population you’re going to have about 1/2 false positives. See the university’s chart below. If my detective work is correct, all 109 Campus Health tests below were on people who had come up positive in previous days/weeks on the Antigen test. If true, then there’s about a 60% false positive rate (which makes sense based upon the possible specificity of the Antigen test and the rate of infection on campus). Will keep watching this, but it seems less concerning than before.
Interesting data from the first week or so back at schools. University of Arizona had about 126 cases reported today while the entire rest of the county had around 30. Test positivity (a bad metric the way most government groups are trying to use it) has been about 2.5% at U of A since 7/31 until today where it jumped to 8.2%. Its hard to make much of a judgement from this as I don’t have any of the data between 7/31 and today, but that might be surprising. It does appear to be a large jump in tests from the average since 7/31, which might indicate there are more people feeling sick enough to get tested. I can’t tell much more because U of A’s data is kind of sparse and I can’t find numbers to indicate how many students are on campus right now. ASU, however, gives us a better wealth of data about their cases…
Here’s from the Arizona State University COVID page.
First off, we don’t have good numbers from ASU on how many tests were given to arrive at the numbers listed above.
Cases for ASU faculty and staff appear low compared to their likely demographic in the rest of the state. The number listed is 0.2%, but it isn’t clear if that’s a cumulative count or an instantaneous count of active cases. Even if it is the count of Active Cases and these staff are in quarantine, that is still far lower than the instantaneous count of the students Active Cases (see below, it’s 3.4%). The demographics that ASU employees are most likely to be in ranges from 20 to 64, which represents 3 demographic categories the state has been collecting case data on. All three of these are experiencing something on the order of 3.6% cumulative infection rates (or 36 out of 1000 as my chart below shows), so we would expect their current outbreak rates to be similar. There may be a data collection divergence between ASU collection and the State of Arizona collection (perhaps some faculty and staff tested positive over the summer at a CVS but didn’t tell their employer?). However, this is still a fairly big gap. Does it mean that university employees are less likely to get COVID than their same-age counterparts outside the university? What about their potential exposure to sick students? More to follow, but this does present some interesting questions.
The 1.3% positivity across all 74,500 non-online students is probably a case where the denominator is artificially large. How many of these students left campus and have been sheltering at home? I don’t think this number is relevant.
The more interesting indicator is the 336 positive students out of 9662 living on campus at Tempe. It’s unclear what the time period is that ASU has been collecting this, but the fact that they are apparently currently in isolation sounds like they are Active Cases, not cumulative cases. If true, this is a very high rate of Active infection for the Tempe campus (3.4%) and is about equal to the infection rate their age demographic has experienced cumulatively in the state since the start of the outbreak. This would be a big jump (it would account for 1/2 of the cases in the County on 9/2) and it appears that we can see it on the Maricopa County case chart.
There are 32 cases out of 1195 in the ASU Downtown and ASU west campuses. Again, well have to assume that these are active cases since they’re referenced as being “in isolation”. Therefore, 2.6% of the students at these two campuses are currently sick with COVID-19. Compare to 3.4% from Tempe and 0.2% in the faculty and staff.
Finally, and my favorite stat here is that there are 0 cases out of 771 students at the ASU Polytech campus. That of course is 0%. What do we take from this? Nerds are more careful? They wash their hands more? Or maybe there’s just not much partying going on at this campus (it has various government agencies sharing the campus along with other technical education programs).
as of 9/2/20, the cumulative count of cases by age group measured as a count out of 1000 people in that age group. cumulative total case count for Maricopa County. Note the measurable increase in slope on 9/2. Perhaps this is due to the cases on the ASU campus.
This above chart is a bit different because it shows the cumulative number of COVID-19 cases in the state for each age demographic divided by the total population in the state of that age group. This allows us to see how COVID-19 is really affecting the different age groups. A few things that are interesting…
1) The true rate of infection for 3 groups is pretty much the same. The 20-44 age group always has the most cases by raw number, but when you consider there are more of them than any other group, you can then see that they’re not excessively effected compared to other groups.
2) The 65+ group has less cases by close to 1/2 of the top groups. This makes sense because I’d imagine that many of them are being more careful due to the severity of the disease for those groups.
3) The under 20 group is much less likely to get infected. This may partially be because a good number of people in this group aren’t economically active and schools have been closed. Or maybe their immune systems are better tuned to the disease and they never show symptoms. Remember these cases are confirmed by tests, so there may be many people who never show symptoms and never get tested who have been infected.
4) I’m very surprised at the lack of effectiveness of the state measures taken in late June. Pretty much every county in the state issued facemasks in public proclamations and the economy was essentially closed again. Still, we see no impact on cases for basically 6 weeks, then all of a sudden all the age groups show a marked decrease (the red vertical line). I truly expected the state measures to show a dramatic effect in 2-3 weeks (since the cycle time of the disease ia about 18-21 days). Very strange, but similar to what has been seen in other regions. Sweden (see below) had a sharp downturn in cases just like this and they had very few state measures taken. Makes me curious about what is really causing the rates to make such sudden changes.
5) Testing: The chart below tells the testing story. People have noted to me that media outlets are suggesting that falling case numbers have to do with the decreasing numbers of tests. The way I look at this data is this: First off, testing in Arizona is not strategic and random. People get tested because they feel sick or they work in jobs where there’s a high probability that they could be sick. This means the numbers of tests conducted has a high severity bias. So what this data might be telling us is that every day there are fewer people who feel sick who decide to go get tested and that an even lower percentage of these people are actually confirmed positive with COVID-19. This seems to indicate to me that the decreasing case numbers are probably legitimate.
Number of tests and % positivity. Note that I have no way of aligning the dates to determine if a positive test today = a confirmed case today. We’re counting on the effect of big data to give us information despite this.
I’ve been seeing a lot of confusing excess deaths charts floating around on Facebook and in the news media. The consistent story is that 2020 is seeing excess deaths due to COVID-19 over previous years. So I decided to see if I could replicate this using CDC data. Fortunately CDC seems to be actively (?) counting COVID and COVID-like deaths for 2020 at this URL. Also, CDC’s “Wonder” system allows one to pull data from previous years. So my strategy was to take deaths from the two most recent years in Wonder (2017-2018) and average these deaths to get a baseline that we can compare 2020 deaths to. Of course we are just over halfway through 2020, so I have to account for that as well (it’s interesting because we only have about 5-6 months of COVID-19 deaths, but we have an additional month or two of other deaths. I just assume that we’re halfway through our deaths to simplify.
Results
First, doing the work to connect this data resulted in some interesting insights. Below I show the state demographics sorted by the Excess Deaths in 2020 and we see some surprising things.
Table showing Excess Deaths in 2020 compared to an average of deaths from 2017-2018. Also shows the percentage of 2020 deaths coming from COVID-19, Pneumonia, and Flu compared to the 2017-18 average. Data from CDC, therefore it’s probably about a month old
What does the table reveal? First off we see that the demographics that have the highest number of excess deaths in 2020 compared to the 2017-18 average are the older demographics from DC and New Jersey. This makes sense due to the large numbers of deaths per capita in these states. We also note from this data that there are clear gaps in the CDC data because we’re not seeing New York at the top of the excess deaths list. Right now the CDC data for 2020 seems to only have about 1/3 of New York’s deaths captured. This is a big liability with using CDC data…
Another interesting thing to note are the rows with yellow highlighting. These are all demographics in states that have had very little COVID-19 death impact compared to the 2017-18 baseline. However, they still have a high Excess Death number. There are many reasons why this might be the case, but I’m suspicious because many to most of these state/age demographic groups are also at high risk from suicide. I wanted to check this by looking at 2020 suicide statistics, but apparently no one has this data. The most recent suicide statistics you can find are in 2018 CDC data.
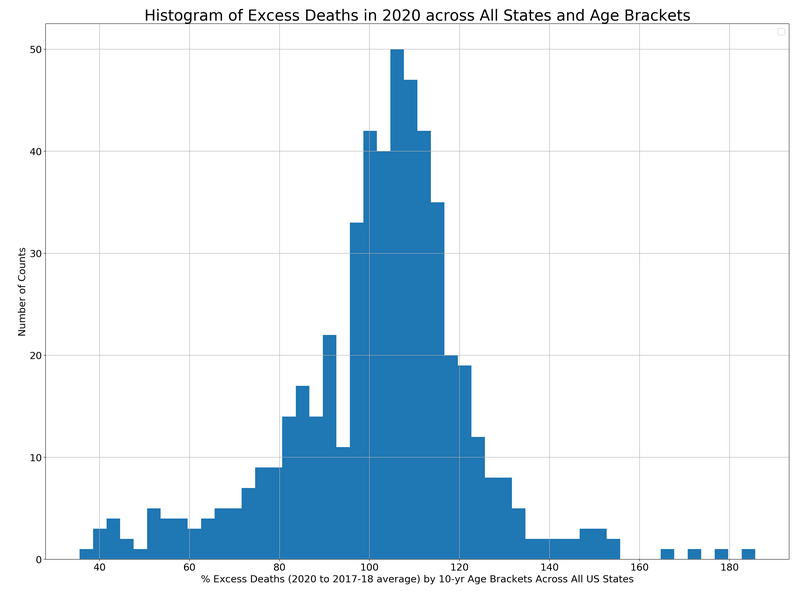
Histogram of Excess Deaths
Now I want to evaluate what the distribution of excess deaths looks like across all demographic groups in all states. This will give us an overall sense of the probability of having excess deaths in 2020. I do this with a histogram. See diagram below.
Histogram of Excess 2020 Deaths compared to 2017-2018 baseline. CDC Data 8/12/20
This histogram shapes up to look a lot like a Gaussian Distribution with a mean around 110% and a standard deviation of roughly 15%. This means roughly 70% of our demographic groups in the country are projected to have excess deaths ranging from 95% of the 2017-18 baseline all the way up to 125% of the baseline. This indicates to me that yes, 2020 is a worse year for deaths. Based off the data in the table above, we can safely assume that in many regions this is due to COVID-19. The data shows that for some states and their older demographics, COVID-19 is projected to exceed the 30% of total deaths that heart disease consistently accounts for.
Notes:
I’ll mention again that I have accounted for the roughly 1/2 of a year of death data that we’ve collected in 2020.
I averaged 2017 and 2018 deaths to make sure that I didn’t pick a year with unusually high deaths (2017 had a lot of flu deaths) as my baseline. It is not possible to get this data from 2019 off the CDC site yet.
Yes, the CDC data is spotty. Normally the older data is pretty solid, but newer data always has data staleness issues with the CDC. They call this provisional death data to make the point that they’re slow and we shouldn’t assume it’s as good as the older data is.
Remember, since I’m assuming the death rates will continue at a similar rate throughout the rest of the year, this is a projection.
It is very possible that COVID-19 deaths will accelerate or decelerate and the excess deaths will look different at the end of the year than I project right now.
Conclusion
Data truly gives us reason to believe that 2020 has been an unusually high year for deaths. This is unsurprising due to the focus our news media gives to COVID-19 cases. The mean value for excess 2020 deaths over the 2017-18 baseline is about 110%. This means that if there were 100 deaths in a region for the first 6-7 months of our baseline, on average, demographics have seen 110 deaths in 2020. This may seem like a small number, but an additional 10% is pretty significant and adds up.
Some demographics in some regions will see COVID-19 be one of their top overall sources of death in 2020. About 15% of the rows in my table (that I just show just a small portion of above) will have COVID-19 account for more than 15% of their total deaths. To give an idea of the significance of that, normally heart disease accounts for 30% of the total deaths in the country and cancer accounts for 25%. The next highest source of death across the board is accidents at 8%. Flu and Pneumonia normally account for around 2.5% of total deaths. Recall too that the CDC numbers seem low, so this percentage is likely to increase.
This article started with a simple graphic that I posted on Facebook for people to comment on.
Deaths across Age Demographics comparison for Arizona, Sweden, and NYC. Data from AZDHS, NYC Public Health, and Statistia. 8/7/20
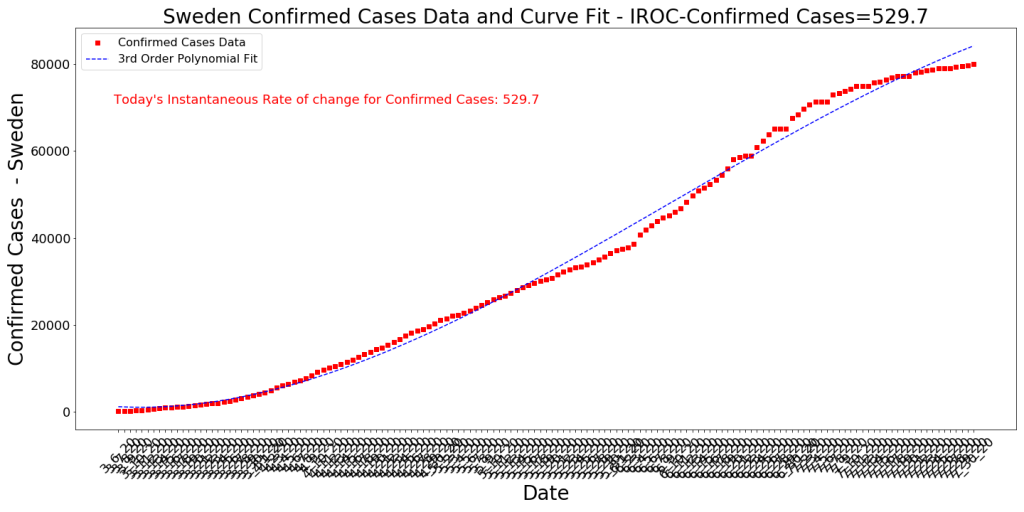
I got the idea from a post on Linkedin that compared Sweden’s deaths with those in the US and it was really surprising, based on the constant media denigration of Sweden and their modified lockdown strategy. As the data shows above, despite not locking down their under 65 population, Sweden has to date had very few deaths under age 65. Less so than regions where lockdowns of the under65 populations were intense (and in Arizona’s case, happened twice). This comparison also made sense due to population size similarity between the regions (Arizona is about 7.3M, Sweden about 10.2M, this part of NYC is about 8.4M). Another interesting datapoint on Sweden’s unique management of the COVID outbreak is pasted below. Around early July the case rate adjusted sharply and now new case growth is a very small number per day. This is interesting that the case growth slowed so quickly, especially in light of their strategy to not close schools, restaurants, etc.
Sweden Cumulative Confirmed Cases since early March 2020. Data from JHU. 8/1/20
Population Density
One of the persistent questions about this comparison was whether it had merit since NYC is much more dense than Sweden and Arizona (I assume that’s true, but haven’t looked at the numbers). So since NYC is more dense, it makes some intuitive sense to us that the density factor may account for a greater number of deaths. Does it?
Correlations of different societal and geographical factors with COVID-19 Cases and Deaths has been one large area of interest of mine through this outbreak. I have reported on this in this blog multiple times as the outbreak has spread. In the past, I observed that population density is slightly correlated with case count across the globe but is basically uncorrelated with deaths. Does this still hold today now that the virus has spread to new places?
Correlation of Various Factors with Normalized COVID-19 Death Count
COVID-19 death and case data from JHU, Other data from the World Bank.
Note that the factor most positively correlated with Deaths in a region is the number of Cases in the region normalized by the population. This is followed closely by the Instantaneous Rate of Change of Cases (the slope of Case Growth). You would expect this to be the case, but it’s a bit surprising to see that the number of cases in a region is only just over twice as correlated with deaths as the Body Mass Index mean for males! This would also indicate that there are regions where the BMI of the population has had more of an impact on deaths as the case count in the region. As evidence that high case count does not always lead to high deaths (and conversely that lower case counts can lead to high deaths, see the chart of Arizona counties, where we have results all over the board. The counties with the highest death rates are generally the ones with lowest population density and highest pre-existing morbidities. Some counties (cities) have very high case counts and low to moderate deaths. Other counties have low case counts and high deaths. It’s all over the map.
Arizona COVID-19 Stats by County
Arizona stats by county, 8/7. Data from JHU.
Conclusion
I did the original assessment to compare what has happened in Sweden vs. other regions largely because of the negative media attention that Sweden has received from their COVID-19 lockdown strategy. As it turns out, for populations under 65 (the ones who were actually not on lockdown) there has been very few deaths (but lots of cases). This is surprising considering that in Arizona and NYC, government interventions such as lockdowns, closing businesses, and mandatory face masks have been credited with slowing the growth of the outbreak. There are many surprising things I’ve noticed through this time of COVID. I point out a few others in this post regarding the unintuitive role population density plays in COVID-19 deaths as well as the observation that the correlation of COVID deaths with high COVID case counts is much smaller than we would have guessed (I would have suspected 90% or higher correlation).
Overall what does this show us? Our intuition is not necessarily to be trusted and should be assessed more critically using data rather than prior beliefs. The same applies to media reports, which tend to only show data in support of a pre-existing narrative.