In a previous article (link) I discussed how to create and evaluate a simple metric that describes the difference between the number of goals a team is expected to make (using the xG metric) and the actual number of goals they score. I’m calling this difference “luck” because it describes how much a team under- or over-performs the expectations made by the way they play a game. Soccer, perhaps more than other sports, is heavily influenced by these over- and under-performances.
I previously discussed how luck seems to be distributed across teams in MLS and the Premier League both when they are the home team and when they are away. We plotted their mean home luck and away luck against their other metrics that we’ve determined to be predictive, 1) the ratio of xG for a team to xG for the opponent (xG ratio) and 2) the amount the team pays in salary. We could see that teams that have favorable luck at home and/or away tend to perform better. Perhaps this is an example of how a team can “make their own luck”, meaning that perhaps in soccer not all luck is purely random chance. Most likely there are elements buried inside this luck metric that are based off of things we can’t easily measure. Stuff like good preparation, team chemistry, and the two things we’ll evaluate next in this series, the venue a team plays in, and the official overseeing the match. Today we’ll discuss venue.
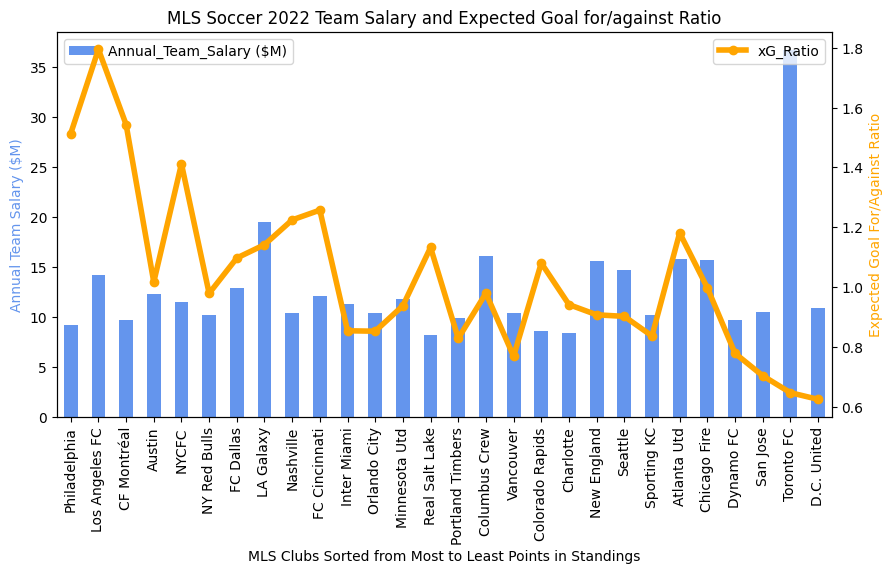
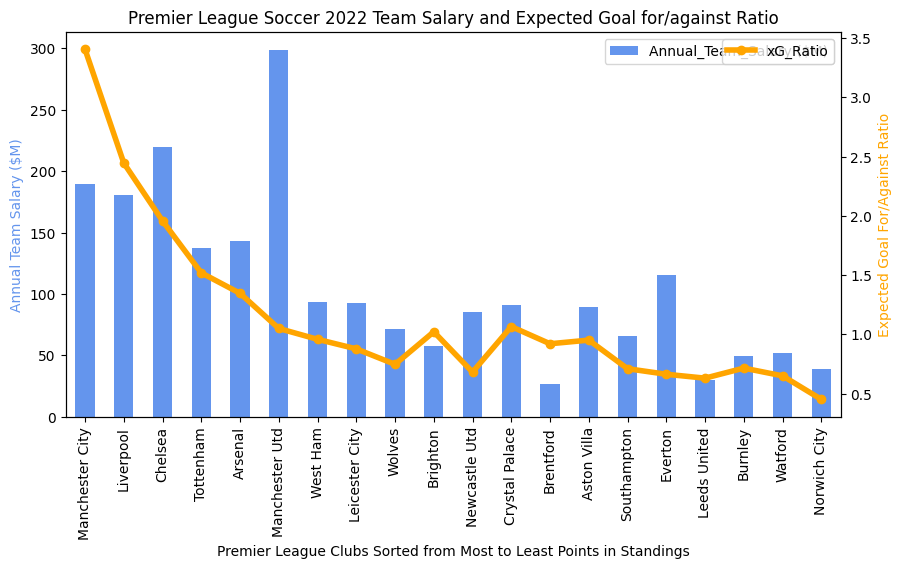
The reason the intersection of “luck” and venue came to my mind was due to a discussion with an MLS player recently about analytics. We were talking about the strange difference between the relationship between the xG ratio and performance across the MLS and the Premier league (see this link to see this difference). He mentioned a number of elements about the MLS that could explain this difference:
- The different ways that MLS teams travel (bus, train, commercial air) vs. the ways that Premier League teams travel (more money = much nicer).
- The long distances that MLS teams travel and the widely-varying geographies and altitudes that British teams don’t have to face. Sometimes these distances, especially if it is to be a longer bus ride, influence a team’s willingness to “get a game over with”.
- The venue. I was not aware of this, but the player mentioned that there were still six teams in the MLS playing on artificial turf. Here’s a wikipedia page providing the details of all MLS stadiums. Sure enough, there are actually seven fields using some kind of turf, ‘Lumen Field’, ‘Providence Park’, ‘BC Place Stadium’, ‘Gillette Stadium’, ‘Mercedes-Benz Stadium’, ‘BMO Field’, ‘Bank of America Stadium’. When I did a simple grouping operation to evaluate the mean luck score for home and away teams on turf and then compare these numbers to games on grass, I see a difference. Stay with me and I’ll describe it.
Breaking down Luck by Playing Surface
2023: Interestingly, in 2023, we see both Home and Away teams performing slightly better in terms of “luckiness” when playing on TURF! This is likely close to how the MLS player imagined the result would be. This means that home teams outperformed their expected goals by a bit more (.229 on turf to .167 on grass) and away teams slightly underperformed their expectations (-0.058 on turf vs. -0.014 on grass). This makes sense that the “turf-based” home team is more familiar with their playing surface and they therefore outperform expectations more then how a “grass-based” team outperforms on their grass surface. Yes, this is confusing, but it appears that turf gives their teams a bigger advantage than grass gives their teams. My guess is that this is based on the fact that there are more grass fields and they are very familiar to all teams. Away teams, however, always seem to underperform compared to home teams and we see this underperformance to be more noticeable on turf. So in essence, in 2023, the data indicates that teams with turf had a measurable advantage at home greater than the advantage teams with grass saw. In 2022, we don’t see these exact results, however, with Home Team luck being a tossup between turf and grass and Away teams still seeing poorer performances (-0.064 on turf vs, 0.161 on grass). Still, this shows a small advantage for the Turf-based teams.
Detailed Views of Luck for 2023 (season still incomplete)
Here are some errorbar plats that will allow us to see some of this detail more clearly. NOTE that stadiums with turf fields have their labels on the plot in red. Other things to be aware of… the vertical lines represent the range of luck results (standard deviation) and the squares represent the mean luck values at each stadium. Nodes with no vertical bars tend to be stadiums where only one game was played, therefore there was no variation of luck. The results are sorted from greatest to least luck.


Detailed Views of Luck for 2022 (season still incomplete)


What Do We See in these Plots??
- The “Luck Slope” for both home and away teams is steeper for 2023 than 2022. My guess is that this is due to the fact that the 2023 season is still being played. It will be interesting to see if the difference in luck between the top venues and the bottom ones flattens out as the season progresses.
- But even though the season isn’t complete, the data from 2023 is interesting. So far, we can see that for the Home Teams, the “red” venues (these have artificial turf surfaces) tend to be more towards the left of the chart. This is the “higher luck” side. Conversely, the same venues that are positive for the Home teams are on the left side of the Away Team chart, meaning that the turf fields are less lucky for away teams.
- If you do a study field-by-field, the “luckier” venues in 2022 are not the same ones seen in 2023. There could be lots of variables other than playing surface that could describe this. Take a look and see what you can uncover! For example, Lumen Field (home of the Seattle Sounders) is incredibly unlucky for the Sounders in 2023 (and is lucky for their opponents!) but in 2022 it was about middle of the road. Despite this unluckiness, the Sounders are 2nd in the MLS Western Division right now! One observation I’d make is that the Sounders are one of a couple of teams where their home luck and away luck do not diverge much. For a good visualization of this, see 2023 chart at this link.
- There are a whole lot of different analyses that could be done using this data. Feel free to discuss in the comments section of the blog! I probably haven’t thought yet about what you noticed!
LINKS to Other Soccer Analytics Entries
- Soccer Analytics Series Intro
- MLS and Premier League Comparison
- Home and Away Luck Metric
- Does Counterpressing Work? Evidence.
- Evaluation of Outcomes using the Luck Metric
- More Analysis using the Luck Metric
- Soccer Analytics in Practice – Youth Soccer Example
- xG and Luck update on recent MLS season